
DX開発事業部の西田です。
Gemini 2.0 Flash での画像生成がパブリックプレビューになり、Vertex AIでも実行できるようになったので早速試してみたいと思います。
Gemini 2.0 Flash 画像生成でできること
テキストから画像を生成
プロンプト:
「背景に花火がある東京タワーの画像を生成してください。」
生成結果:
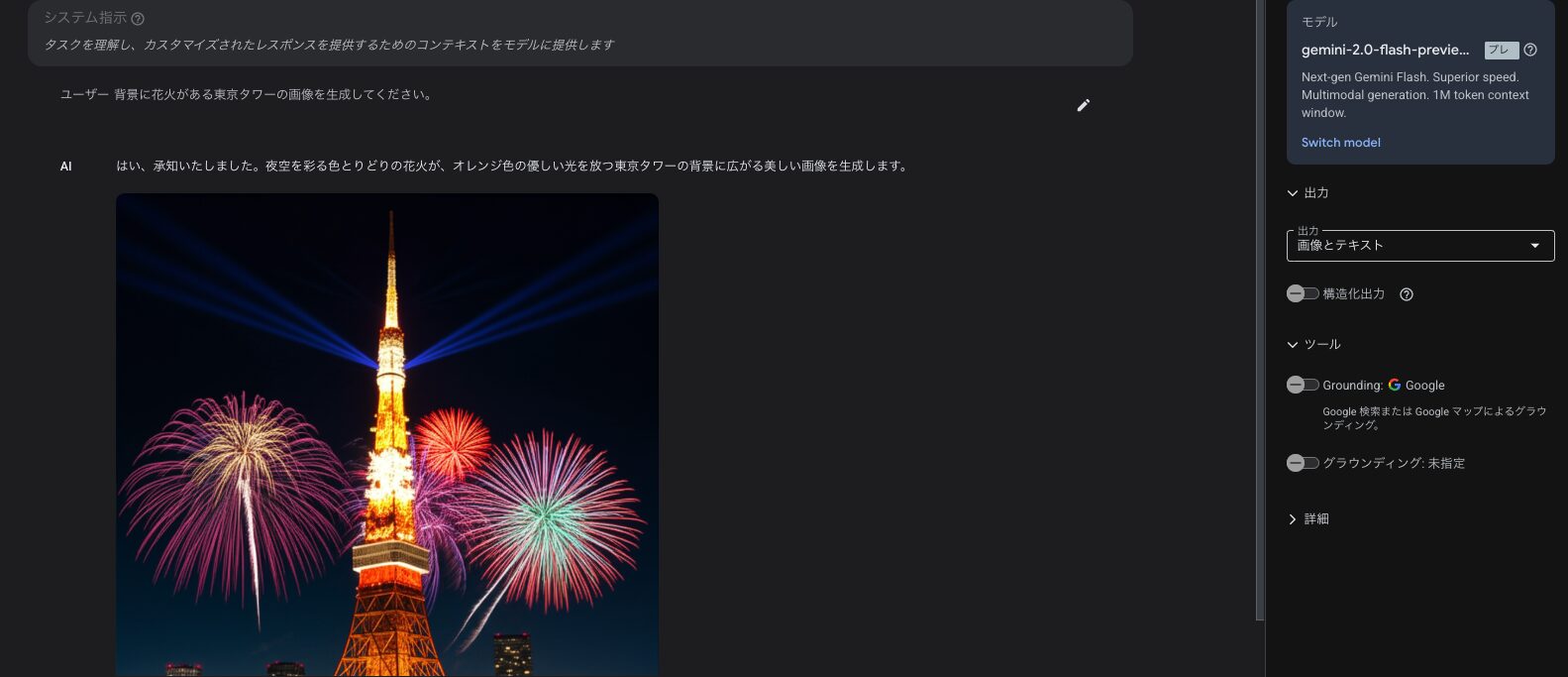
日本語もサポートされています。
画像にテキストを入れる(テキストレンダリング)
プロンプト:
『「クラウドのことならアイレットにお任せ!」というボードを持った笑顔のビジネスマン。』
生成結果:

画像とテキストを交互に生成(インターリーブ)
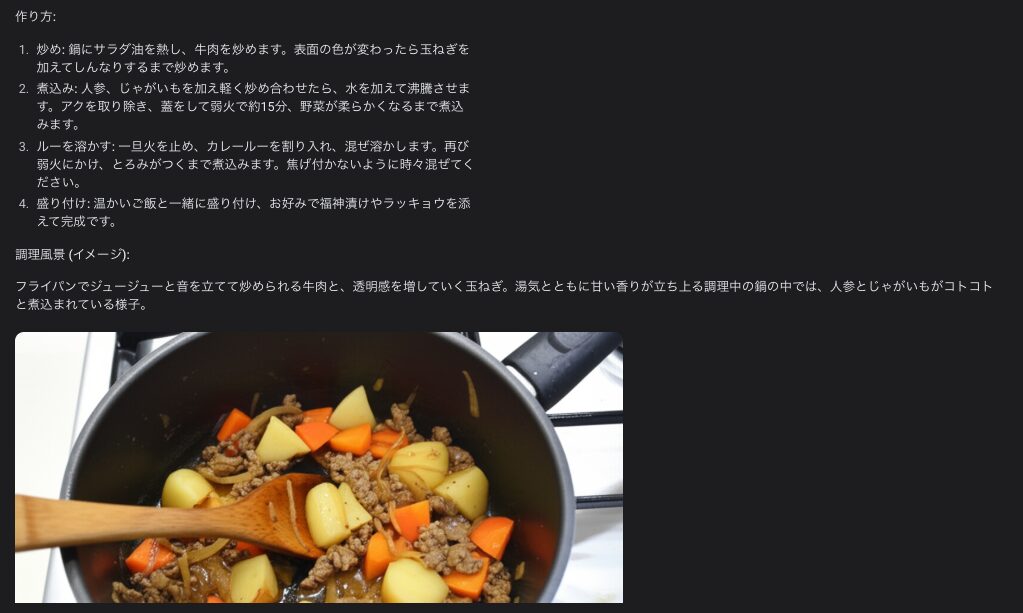
プロンプト:
「おいしいカレーライスのレシピを考えてください。途中の調理風景と完成がわかる画像も一緒に生成してください。」
生成結果:

画像編集
プロンプト:
「スーツの色をピンク色にして。それ以外は何もしなくてよい。」
生成結果:

チャット形式でマルチターンで画像を編集していくことも可能です。
価格
Vertex AI Pricing | Generative AI on Vertex AI | Google Cloud
Discover flexible pricing for training, deployment, and prediction for Generative AI models with Vertex AI. Build and scale intelligent applications efficiently.
トークンベースの価格は次のようになっています。
| モデル | タイプ | 価格 |
|---|---|---|
| Gemini 2.0 Flash Image Generation | 100万入力トークン | $0.15 |
| 100万入力音声トークン | $1.00 | |
| 100万入力動画トークン | $3.00 | |
| 100万出力テキストトークン | $0.60 | |
| 100万出力画像トークン | $30.00 |
画像出力のトークン消費にかかるコストが大きいので注意が必要です。
目安として1024×1024の画像の場合、1290トークンを消費し、画像の解像度によっても異なります。
※参考
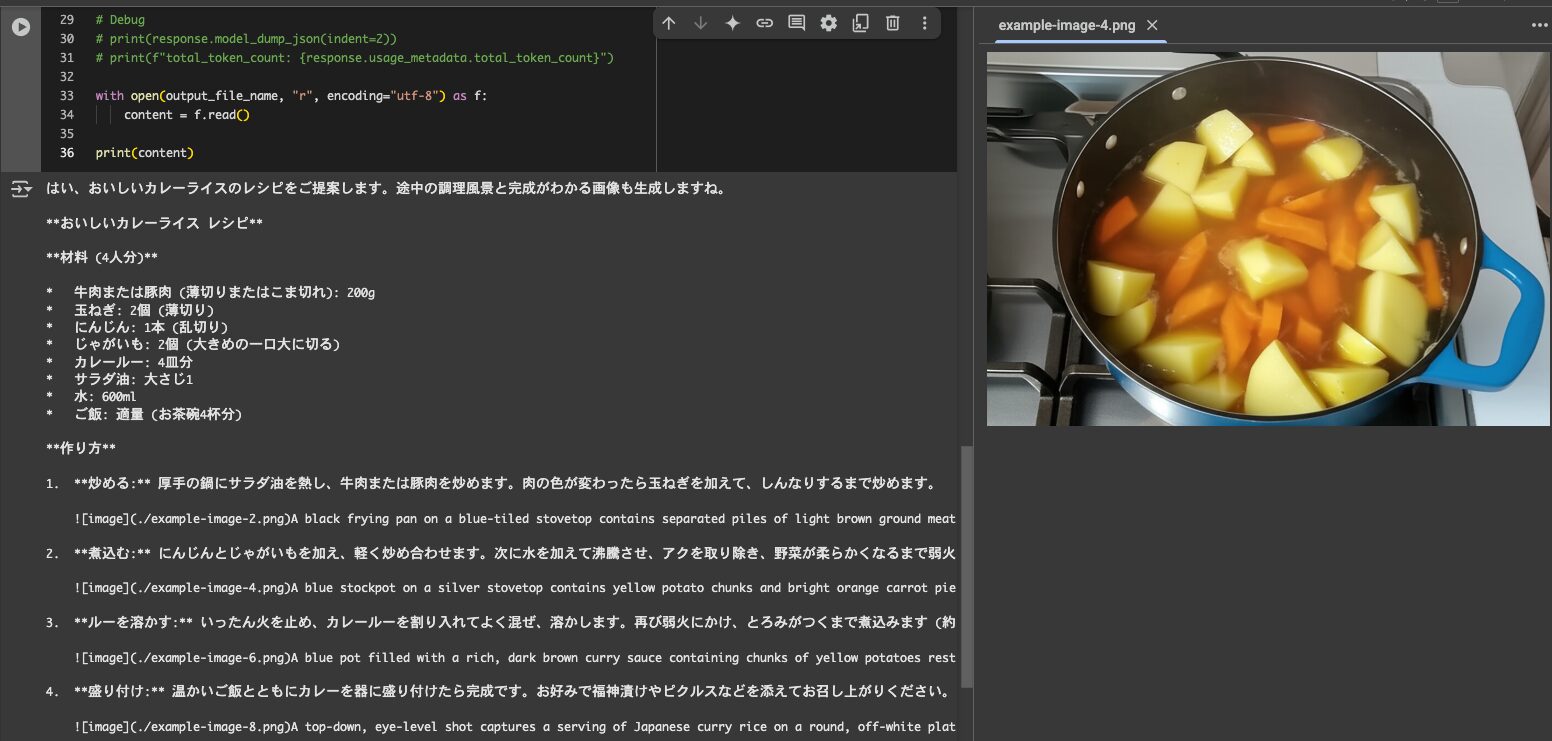
SDKで実行
!pip install google-genai==1.14.0
from google import genai
from google.genai.types import GenerateContentConfig, Modality
from PIL import Image
from io import BytesIO
client = genai.Client(
vertexai=True, project=PROJECT_ID, location=LOCATION
)
response = client.models.generate_content(
model="gemini-2.0-flash-preview-image-generation",
contents=(
"おいしいカレーライスのレシピを考えてください。"
"途中の調理風景と完成がわかる画像も一緒に生成してください。"
),
config=GenerateContentConfig(response_modalities=[Modality.TEXT, Modality.IMAGE]),
)
output_file_name = "output.md"
# 生成されたレスポンスの要素を順番に処理してMarkdownファイルに保存
with open(output_file_name, "w") as fp:
for i, part in enumerate(response.candidates[0].content.parts):
if part.text is not None:
# テキストはそのまま書き出す
fp.write(part.text)
elif part.inline_data is not None:
# 画像データがあれば画像として保存し、Markdownの画像タグを記載
image = Image.open(BytesIO((part.inline_data.data)))
image.save(f"example-image-{i+1}.png")
fp.write(f"")
# Debug
# print(response.model_dump_json(indent=2))
# print(f"total_token_count: {response.usage_metadata.total_token_count}")
with open(output_file_name, "r", encoding="utf-8") as f:
content = f.read()
print(content)
高品質な画像生成モデルはすでに Imagen がありますが、Geminiと統合されることでより直感的に対話を交えた形で画像生成、編集が行えるようになりますね。
生成速度も速く、対話形式でもストレスを感じにくいです。
プレビューなのでまだ安定していないところは少々ありますが、GAやバージョンアップでより改善されることが期待できそうです!




