
DX開発事業部 フルスタックセクションの田村です。
Google Cloud Next 2026 よりセッションの要点解説をお届けいたします。
今回は「Supercharging unstructured data analytics with generative AI in BigQuery」セッションを聴いてきました。
画像・PDF・音声といった非構造化データをBigQuery上でどう扱うか、というテーマです。BigQuery AIという5つの柱のうち「Gen AI functions」に位置するセッションでした。
BigQuery AIの全体像
最初のスライドで全体像が示されました。

BigQuery AIは5つの領域で構成されています。
- Machine Learning:Feature engineering、Model training、Evals、Inference、MLOps
- Gen AI functions:このセッションのテーマ。ObjRef、ai.generate()ファミリー、ai.score / ai.classifyなど
- Search and Vector Search:Vector Search、Keyword search、Hybrid Search
- Agents and assistive AI:Data Engineering Agent、Data Science Agent、Conversational Analytics
- Agent tools:MCP tools、ADK tools、Gemini CLI extensions
BigQueryを単なるデータウェアハウスだけではなく、AIプラットフォームとして位置付ける意図が伝わってきますね。
非構造化データのライフサイクル全体をカバー
セッションの核心となるスライドがこちらです。

BigQueryが非構造化データの「全ライフサイクル」をサポートするという主張で、5つのフェーズに分かれています。
- ACCESS:ObjectRefs(ネイティブデータ型)で非構造化データにアクセス
- PROCESS:ai.generateやai.parse_documentで処理。Optimized modeで230倍少ないトークン・150倍高速化
- RELATIONSHIPS:Knowledge Catalogでリレーション自動発見、BigQueryグラフとしてモデル化
- GROUNDING:AI SearchとHybrid Search、自動エンベディング生成
- ACTIVATE:Conversational Analytics、Multimodal research(Preview April)、MCP Toolsを使ったDIYエージェント
このスライド1枚だけで「今日のBigQueryの全体像」がかなり把握できます。
ObjectRef:構造化と非構造化を同一行に置く

ObjectRefはCloud Storage上のオブジェクトを参照するBigQueryのネイティブデータ型です。
従来は「構造化データはBigQuery、画像はGCS」と分離して管理することが多く、結合が煩雑という課題がありました。
ObjectRefを使えば同一テーブルの同一行に「Session ID / Date / Customer ID / 音声ファイルへのObjectRef」を並べられます。
紹介されていたデモでは商品カタログのImageカラムがObjectRefとして格納されていました。
商品情報と商品画像を同一行で保持し、AI関数に両方を渡してミスマッチを検出するという使い方になります。
「構造化データと非構造化データをまたぐ分析」の実用レベルを一段引き上げる変更といえます。
GenAI関数の3カテゴリ

BigQueryのGenAI関数は3カテゴリに整理されています。
| カテゴリ | 関数 | 特徴 |
|---|---|---|
| General-purpose | AI.GENERATE / AI.GENERATE_TEXT / AI.GENERATE_TABLE | モデル・プロンプト・パラメータを自分で制御 |
| Managed AI | AI.IF / AI.CLASSIFY / AI.SCORE / AI.AGG | BigQueryがモデルとパラメータを最適化 |
| Task-specific | AI.PARSE_DOCUMENT | PDF→RAG用チャンク変換に特化 |
General-purposeは柔軟ですが設計コストが高め。Managed AIは手軽な一方、内部の挙動は隠蔽されます。用途によって使い分ける設計になっているようです。
SQLでLLMを呼び出す(AI.GENERATE)

AI.GENERATEの使い方はシンプルで、構造化出力も指定することができます。
画像の通り例えば患者の記述から名前・年齢などを抽出したい場合は以下のように書けます。
SELECT AI.GENERATE(patient_description, output_schema => 'name STRING, age INT64, ...') FROM mydataset.patient_data;
モデルの選択肢は、Gemini、Claude、HuggingFaceモデルと揃っています。BigQuery GeminiのBatch inferenceはオンライン推論比で50%安く、PT(Provisioned Throughput)サポートもあるようです。
PDFを1行のSQLでRAG用に変換(AI.PARSE_DOCUMENT)

AI.PARSE_DOCUMENTはPreviewの機能でPDFをRAG用のチャンクに分解するための専用関数です。
出力はchunk_id、content、start_page、end_pageで、内部ではGemini Layout Parserが動いており、画像・チャート・複雑なレイアウトを含むドキュメントも処理できるとのことです。
RAGパイプラインを作るとき、「PDFをどう前処理するか」は地味に手間のかかる部分だと思いますが、これが1文のSQLで変換できるならDataformでのオーケストレーションと組み合わせてかなり楽に運用することができる様になります。
Managed AI Functions
Managed AI functionsはモデルとパラメータをBigQueryが管理するカテゴリです。
こちらも使い方はシンプルでプロンプトと入力を渡すだけで済みます。
AI.IF(GA)

WHERE句の条件に自然言語を使える関数です。
-- レビューのポジティブフィルタ
SELECT *
FROM reviews r
WHERE AI.IF("Customer has a positive review of the product", r.review)
-- 広告画像と商品のマッチング(JOIN条件に使用)
SELECT *
FROM ad_images a JOIN products p
ON AI.IF("Advertisement", a.img_ref, "contains product", p.desc)
JOIN条件にAI.IFを使えるのは個人的に面白いと思いました。「この広告画像にこの商品が写っているか」という判定をSQL JOINで表現できますね。
AI.CLASSIFY / AI.SCORE(GA)

-- ニュース記事のカテゴリ分類
SELECT AI.CLASSIFY(body, categories => ['tech', 'sport'...]) AS category
FROM bbc_news.fulltext
GROUP BY category;
-- サポートトランスクリプトのランキング
SELECT * FROM transcripts
ORDER BY AI.SCORE(
"Agent solved complicated problem: {s.transcript}"
) LIMIT 10;
AI.SCOREは自然言語で指定した基準に従ってレコードをランキングする関数です。「エージェントが複雑な問題を解決したケース」といった条件でトランスクリプトを並び替えるといった使い方ができます。
AI.AGG(Public Preview)

GROUP BY単位でセマンティック集計をかける関数です。LLMのコンテキストウィンドウを超えるデータ量に対してスケールするのが特徴とのことでした。
SELECT t.by, AI.AGG(t.text, "Analyze these posts and identify primary topics") AS common_topic FROM `bigquery-public-data.hacker_news.full` AS t GROUP BY t.by
デモではHacker NewsのユーザーごとにどんなトピックのPostが多いかをGROUP BYで集計する方法が紹介されていました。
Optimized modeによるトークン削減

AI.IFとAI.CLASSIFYに「Optimized mode」(Public Preview)が追加されました。
通常は1億行あれば1億回LLMを呼ぶところを、Optimized modeでは最初に少数サンプルで『このデータならこう判定する』というパターンをBigQueryが学習し、あとは軽量な処理で残りの行を一気に判定させることができます。
画像の通りOptimized modeが導入されることで以下のような削減効果が出ています。
- 230倍:LLMを行ごとに呼ぶ場合比でのトークン削減
- 150倍:クエリ実行速度の向上
- 数十億行:1クエリで処理可能な行数
数億行規模のデータにAI処理をかけるとコストが跳ね上がるという問題に対応できます。
ちなみにここで選択できるモードはMINIMIZE_COSTとMAXIMIZE_QUALITYの2択からになっています。
BQにおけるエンベディングモデル
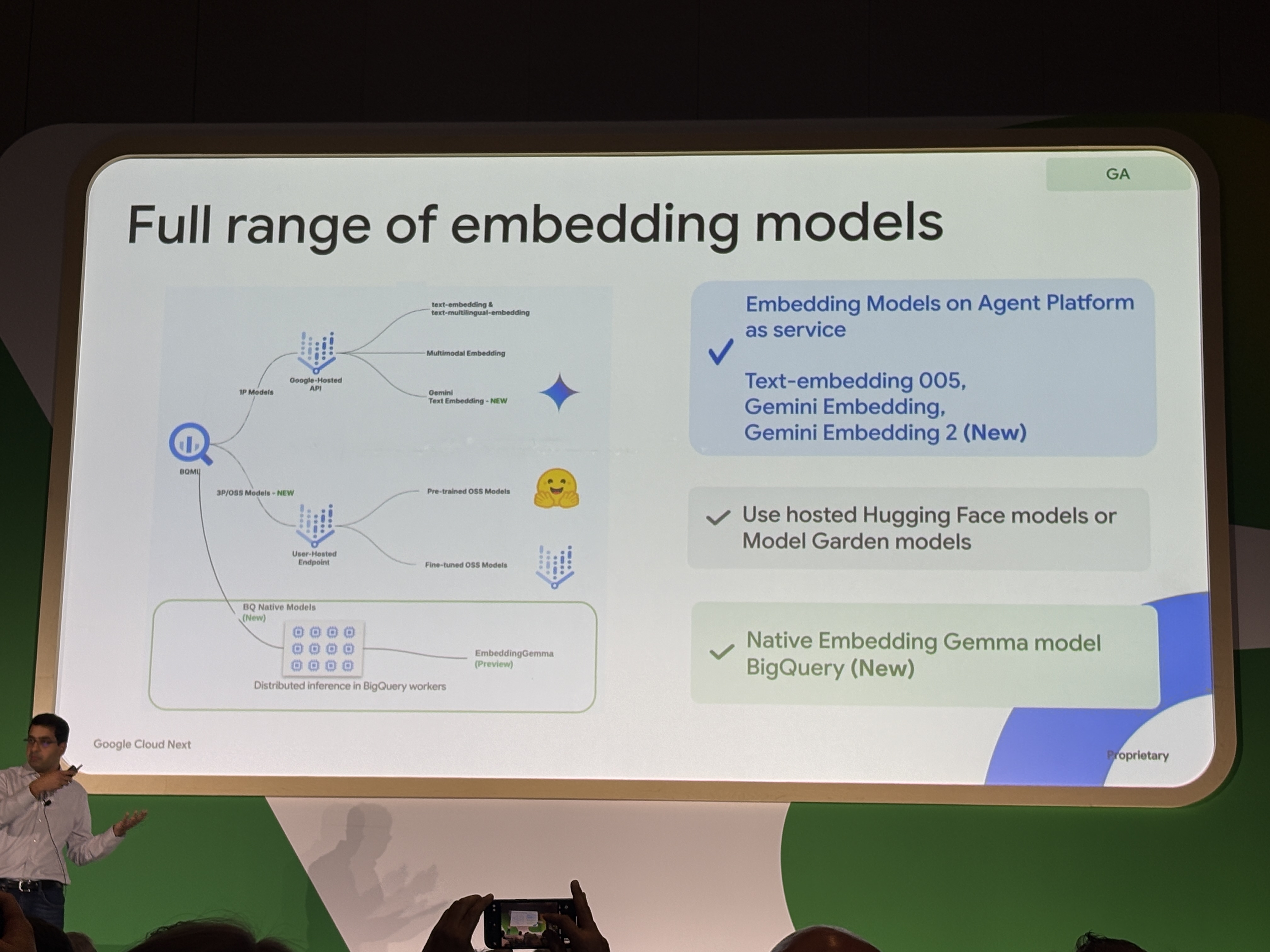
以下のエンベディングモデルを選択できます。
- Text-embedding 005
- Gemini Embedding
- Gemini Embedding 2(New)
- HuggingFaceモデル
- EmbeddingGemma(Preview)
ここで注目なのはEmbeddingGemmaです。
エンベディングモデルがBigQueryのWorker内で直接実行されるため、外部APIへの接続が不要となります。またモデルファイルのインポートも不要となるのでBigQueryの予約キャパシティから実行されます。
コストコントロール(Coming Soon)

AI関数のコスト管理機能もComing Soonとして紹介されました。
AI.COUNT_TOKENS():実行前にトークン数を見積もる- プロジェクト・ユーザーレベルのトークンハードリミット(1日あたりの上限設定)
- セッションレベルのトークン上限
SET @@ai.max_input_tokens = 10000000; SET @@ai.max_output_tokens = 2000000; -- SQL query here
本番運用でAI関数のコストが予算を超えるリスクを抑えるための機能です。AI関数がGAされる前にあらかじめ整備されるのはありがたいところです。
事例:Snapchatのコンテンツモデレーション

顧客事例として紹介されたのはSnapchat(Snap Inc.)のコンテンツモデレーションです。
- ユーザーがStories/Spotlight/Mapsにコンテンツを投稿
- サンプリング対象になったメディアURIとメタデータをBigQueryに格納(Object Tables使用)
- BigQuery AIで
HIGH_RISK/LOW_RISKに分類(AI.GENERATE_TEXT()+OBJ.GET_ACCESS_URL()+FARM_FINGERPRINT()) - HIGH_RISKと一部のLOW_RISKを人間によるラベリングに回す
このワークフローはBigQueryとAirflowで1時間ごとにオーケストレーションされているということです。高スループット・低レイテンシが求められるコンテンツモデレーションで本番稼働しているのは、一つの実証になりますね。
BigQueryネイティブの時系列予測(AI.FORECAST)(GA)

TimesFMは時系列予測のための基盤モデルで、すでにGAとなっておりAI.FORECAST関数にデータを渡すだけで予測が返ってきます。ドメイン・ルックバック期間・頻度を問わず入力でき、出力は任意のホライゾン・信頼区間に対応しています。
今回新たに異常検知(Anomaly detection)機能がTimesFM経由で追加されているようです。
Connected SheetsでTimesFMを使う(GA / 異常検知はAlpha)
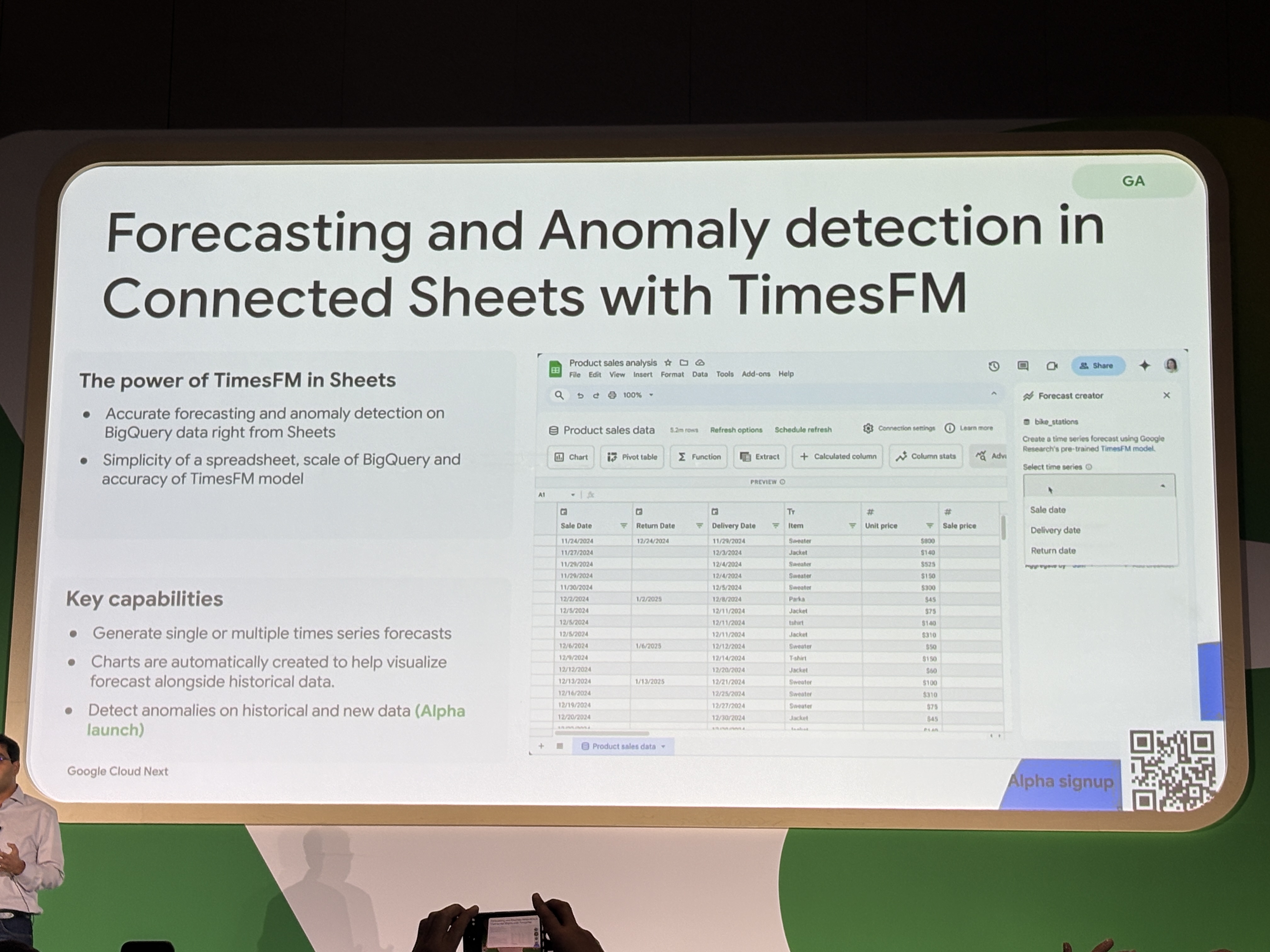
Google SheetsのConnected Sheetsから、BigQueryのデータに対してTimesFMによる予測をかける機能がGAになりました。
スプレッドシートの使い勝手でBigQueryスケールの予測が実行できます。チャートも自動生成されるため、アナリストが分析環境を変えずに予測を活用できる点が実用的です。
XGBoostを超えるゼロショット分類(AI.PREDICT)(Preview)

Tabular FMは表形式データ向けのゼロショット基盤モデルです(Preview)。AI.PREDICT関数1文で、バイナリ分類・多クラス分類・回帰に対応します。社内ベンチマークではカスタムトレーニングしたXGBoostより精度が高いという結果が出ているとのことでした。
SELECT * FROM AI.PREDICT ( TABLE labeled_transactions, -- training data TABLE new_transactions, -- prediction data model_name => 'tabularFM', label_col => 'is_fraud' );
最大5,000件のラベル付きデータと100の特徴量で動き、推論は数百万ポイントまでスケールします。またモデルのトレーニングもインフラ管理も不要で、SQLだけで完結するのが特徴です。
Conversational Analytics
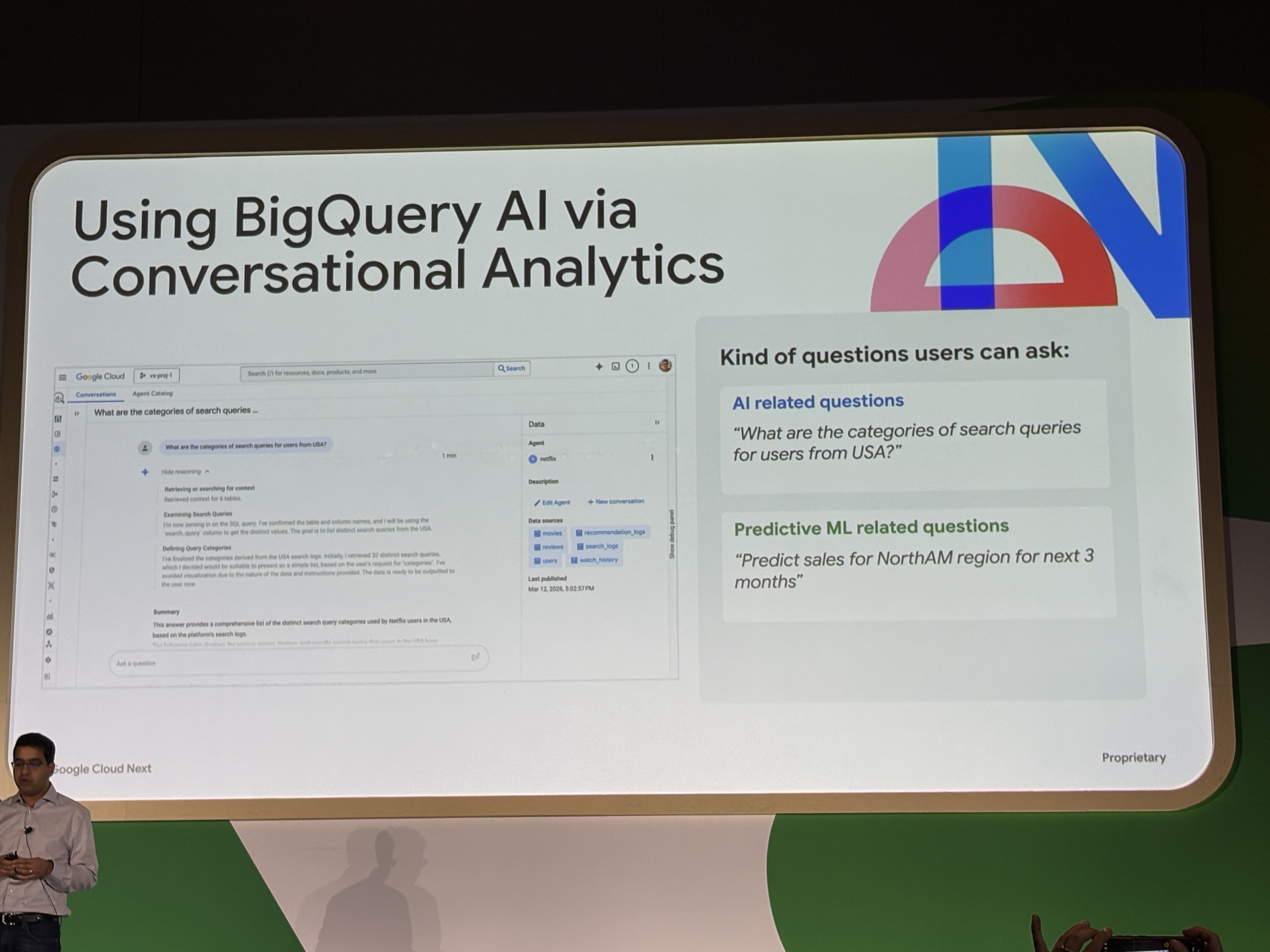
Conversational Analyticsは自然言語でBigQueryに問い合わせる機能です。
例えば「米国ユーザーの検索クエリのカテゴリは?」のようなAI関連の質問から、「北米向けの次の3か月の売上予測をして」といった予測系クエリまで対応しており、内部ではTimesFMやAI関数を組み合わせて実行するためユーザーはSQLを書かずに分析を行うことができます。
セッション全体を振り返って
Google Cloud Next ’26でのBigQuery関連の発表は「体系」としてよりAI/MLのワークフローとしてデータの準備から利用までを容易にするためのアップデートが多かった印象です。
ObjectRefによって非構造化データを扱えることで、AIワークフローにおいて効率よくデータを活用することができますね。
BigQueryのAI関数群がSQL上の処理レイヤーとして組み込まれ、そしてエージェントやConversational Analyticsが活用のレイヤーとして乗っかる構造になっているように感じました。
冒頭でも述べたように単なるデータウェアハウスとしてではなく、AI/MLワークフローを支える基盤としてまだまだ成長中のサービスだと思います。




