
DX開発事業部 フルスタックセクションの田村です。
Google Cloud Next 2026 よりセッションの要点解説をお届けいたします。
今回は「NoSQL for modern apps and AI: The future of Memorystore, Firestore, and Bigtable」セッションを聴いてきました。
Memorystore・Bigtable・FirestoreのNoSQLに関するアップデート情報が多数紹介されていました。
Google Cloudのデータベース

冒頭ではGoogle Cloudのデータベースの一覧が表示されましたが、改めてみると本当に多くの種類のデータベースサービスがあります。
そしてこれらのサービスはユースケースごとにうまく使い分けが出来ていますね。
Memorystore
MemorystoreはGCPのトップ100社のうち95%が使っている、というのがオープニングの一言でした。
マイクロ秒のレイテンシと数百万TPSを実現しながら、ゼロダウンタイムでスケールできます。そしてAIアプリにおいてはコンテキスト保存やセッション管理がこのレイテンシ特性と相性が良いです。
Valkey 9.0 GA
Next ’26に合わせてValkey 9.0のGAが発表されました。

パイプラインプリフェッチで40%向上、ゼロコピーレスポンスでさらに20%向上で合わせると単純計算でおよそ1.68倍のスループットになるようです。
他にも「Hash Field Expirations」が追加されました。これはハッシュのフィールド単位でTTLを設定できる機能で、「セッション情報の一部だけ有効期限を変えたい」といったケースに使えます。
また「Atomic Slot Migration」という機能はValkey/Redisクラスターのスロット再分割時のダウンタイムを回避するもので、運用面での安心度が上がります。
ノードポートフォリオの大幅拡張(GA)

これまで最小1.25 GBからだったものが、最大27.5 TBまでカバーするようになり、ノードの選択肢が今回のGAで大きく広がりました。
大きく3つのカテゴリに整理されています。
- Dev & Micro-Workloads:開発・テスト向けの小さいサイズ(Shared-Nano〜Custom-Mini)
- Compute-Intensive AI:AI推論など計算負荷が高い用途(Standard-Small〜Standard-Large)
- Internet-Scale Memory:超大規模用途(Highmem-XLarge 58 GB、Highmem-XXLarge 110 GB)
今回の新規追加はHighCPU-Medium、Standard-Large、Highmem-XXLargeの3ノードタイプです。
ネイティブモジュール対応(GA)

VSSモジュール(ベクトル類似検索)、JSONモジュール、Bloom FilterモジュールがValkey 8/9でGAになりました。
このVSS機能がGAになったことで、MemorystoreがGenAI・RAGアプリのベクトル検索インデックスとして本番利用するための準備が整ってきたということですね。
オンラインマイグレーション(Preview)

自社管理のRedisやValkeyからMemorystore for Valkeyへの無停止移行機能がPreviewになりました。
PSC(Private Service Connect)経由でネイティブレプリケーションを使いながらデータを同期し、最終的にカットオーバーするフローになっている様です。
既存のRedis/Valkeyクラスターを抱えているチームにとっては、ダウンタイムなしに移行ができるという点では心理的ハードルが下がる機能だと思いました。
データベース周りの機能ではほぼ必須の機能ですね。
Bigtable

ピーク時で70億QPSという数字を説明されました。通常のシステムではなかなかみない数字ではありますが、Gmail・Google Maps・YouTubeがBigtableで動いていると考えると少し想像はできるかなと思います。

こちらはシングルテーブルで1.6京行(Quadrillion rows)、シングルデータベースで2億5千万QPS、シングルテーブルで1エクサバイトという数字が示されており、上限値ではなく実際に動いているデータベースの規模だそうです。
一般的なシステムでは聞き馴染みのないデータ量やQPSをサポートするという点から、分散NoSQLとしては、Bigtableは別格の実績を持っていることが分かりますね。
In-memory Tier(Preview)

今回のBigtable最大の発表がIn-memory Tierだと思います。これはRAM・SSD・HDDの3層構造で構成し、アプリケーションからは単一のAPIで透過的にアクセスができます。
イメージとしては「キャッシュを別サービスとして立てる」のではなく、Bigtableのストレージ層にRAMを追加する設計です。

対象行の読み取りで10倍安価で、単一行で12万QPS、レイテンシはサブミリ秒となっているため、ホットスポットになりやすい行へのアクセスが集中したとしても、In-memory Tierが吸収してくれます。
以下はアーキテクチャの全体像となっています。

ベースノードの上にRAM層が追加されていることが分かりますが、In-memory TierはCustomer VMからアクセスすることでデータベースのCPUリソースを消費することなく読み取りができる様になっている様です。
その他の新機能

まとめて紹介された6機能です:
- SQL Pipes(GA):ML・時系列分析向けのパイプSQL構文
- 地理空間クエリ(GA):70以上の関数、GeoJSON/KML/WKT対応
- ウィンドウ関数(GA):移動平均・累積和・パーセンタイルなど
- 連続マテリアライズドビュー(GA):ストリームデータからSQL集計を非同期自動更新、非同期セカンダリインデックスとしても機能する
- Protocol Buffer対応(GA):BigQuery連携でprotobufデータを直接読める
- Pub/Subサブスクリプション(Preview):Pub/SubメッセージをDataflow不要でBigtableへ直接書き込める
中でもPub/Subネイティブ書き込みはDataflowの運用コストを削減できるため、リアルタイムパイプラインを組んでいるチームは注目しておく価値がありますね。
Firestore

Firestoreアプリケーションは月間20億のエンドユーザーにサービスを提供しており、月間アクティブ開発者は75万人。サービス中断なしの弾性スケール、シングルデジットミリ秒の読み取りレイテンシが特徴として紹介されました。
AIエージェントとの統合

FirestoreはGoogle AI Studioに統合され、そこから直接Firestoreリソースをプロビジョニングして、リアルタイム・マルチプレイヤーアプリを開発できるようになりました。
3rdパーティエージェントとの連携もGAされ、CursorやClaude CodeからRemote MCPでFirestoreを操作できます。またFirestore StudioでGemini Code Assistを使った自然言語クエリはPreviewで発表されました。
フルテキスト検索(Preview)
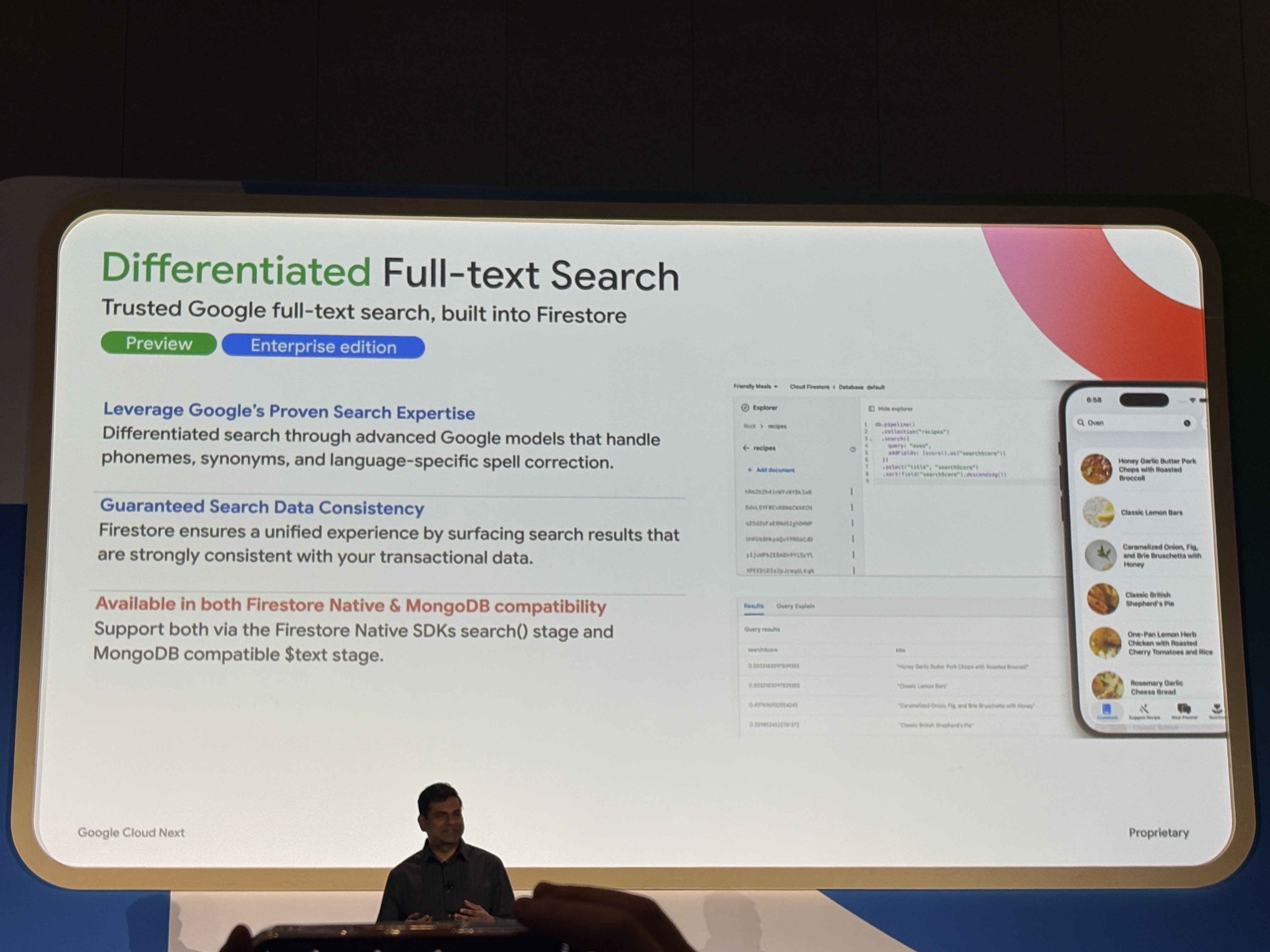
Googleの検索エンジンが持つ音素・同義語・言語固有のスペル修正など高度なモデルがFirestoreのフルテキスト検索としてPreview提供されました。(Enterprise editionのみ)
Firestore Native(search() ステージ)とMongoDB互換($text ステージ)の両方から使えるようになったため、「自前でElasticsearchを運用するか、Firestoreでフルテキストサーチをするか選択肢が出てくる」という状況になってきました。
MongoDB互換のさらなる拡充
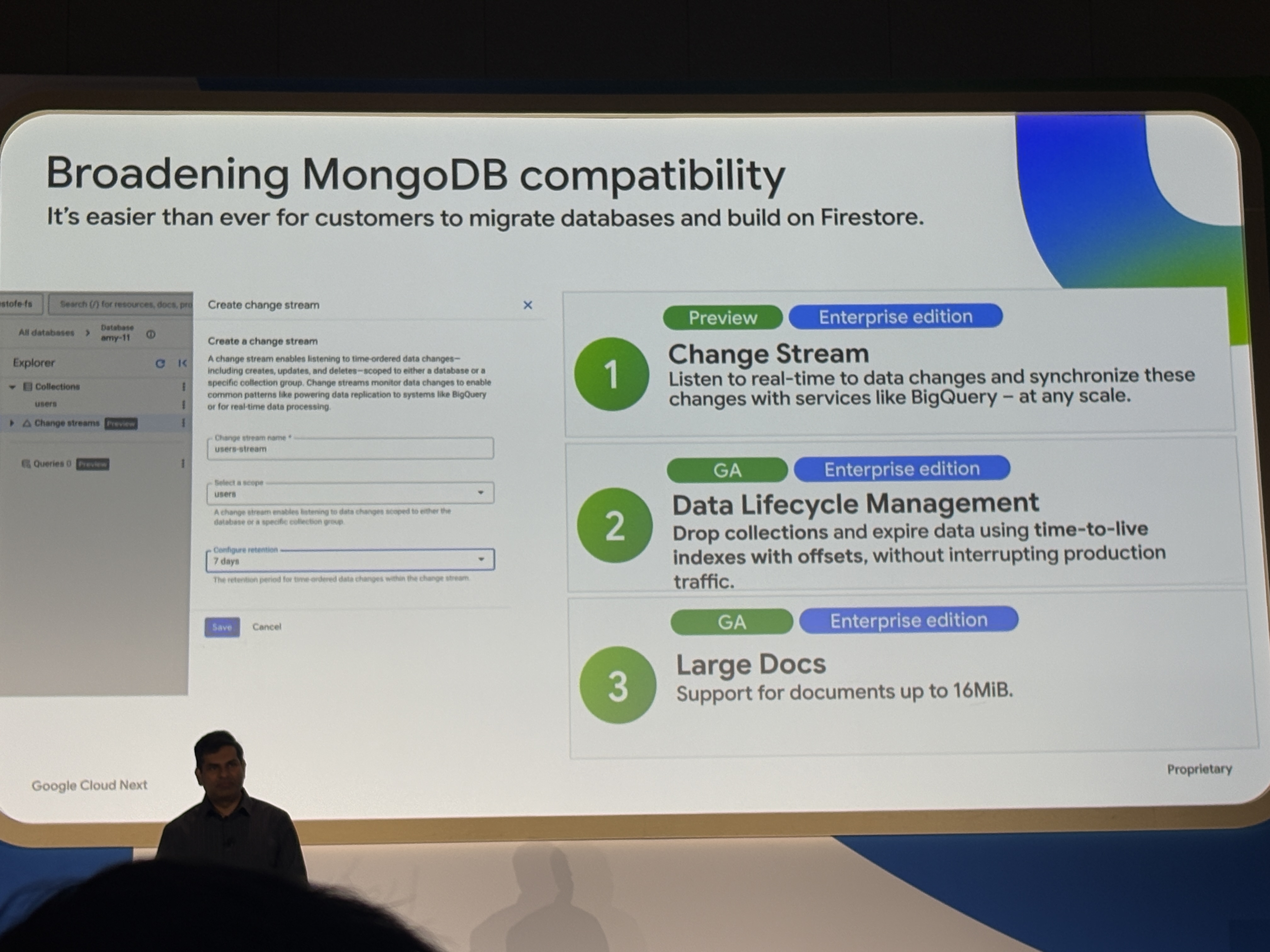
Firestore with MongoDB compatibilityはすでにGAされている機能ですが、今回以下の機能が追加されました。
- Change Stream(Preview):insert・update・deleteをリアルタイムで監視し、BigQueryなどへのデータ同期に使える
- Data Lifecycle Management(GA):コレクションのdropと、TTLインデックスにオフセットを設定したデータ期限管理
- Large Docs(GA):ドキュメントサイズが最大16 MiBに拡大
特にChange Streamは、既存のMongoDBアプリがChange Streamsを使っている場合の移行障壁がこれで取り除かれるとのことです。
セッション全体を振り返って
セッション全体を通じて感じたのは、3つのサービスともAIワークロードへの対応が主軸になっているということです。
Memorystoreはキャッシュをベクトル検索エンジンとしても使えるようになりましたし、BigtableはIn-memory Tierでホットスポット問題を解決しました。また特にFirestoreはGoogle AI StudioやClaude Codeとの連携を発表していましたね。
個人的に一番興味深かったのはBigtableのIn-memory Tierの設計です。「ホットスポット対策にキャッシュを別サービスとして立てる」のではなく、「ストレージ層にRAMを追加して単一APIで透過的に使う」という方向を選んでいるところです。利用ユーザーとしてはアーキテクチャをシンプルに保ちながらもパフォーマンスを改善できる設計ですし、運用コストも抑えられます。
まだPreviewですが、この設計アプローチは他のデータベースにも影響を与えていきそうだと感じました。




