
DX開発事業部 フルスタックセクションの田村です。
Google Cloud Next 2026 よりセッションの要点解説をお届けいたします。
今回は「What’s New in Streaming」セッションを聴いてきました。
ストリーミング基盤(Pub/Sub・BigQuery・Dataflow)の新機能発表がありましたのでまとめました。
ストリーミングデータをエージェントの知能に変える
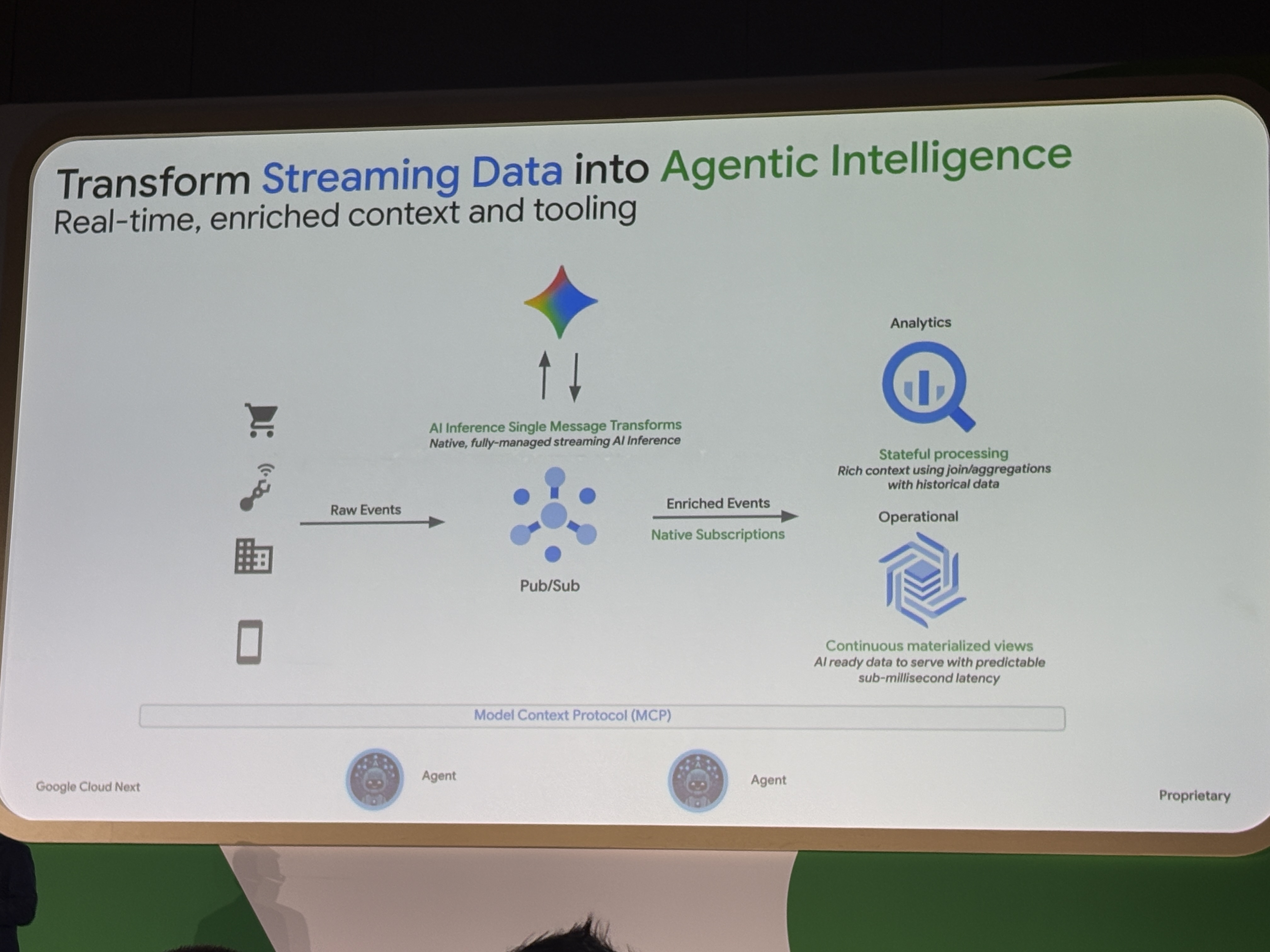
セッション冒頭で示された全体アーキテクチャがこちらです。
Raw Events(IoT、カート、モバイルなど)がPub/Subに流入し、AI Inference SMTでリアルタイム推論が付与されます。その先でBigQuery Continuous Query(Stateful処理)やBigtableのマテリアライズドビューに分岐し、最終的にMCP(Model Context Protocol)経由でエージェントがアクセスする構成です。
セッションでは特に以下の3点が強調されており、エージェントが有効に機能するための条件として説明されていました。
- リアルタイムシグナル(今何が起きているかを知る)
- セマンティックメモリ(生データではなく構造化された知識を渡す)
- 低レイテンシ(エージェントのthink-actループが遅いと意味がない)
これまでのストリーミング基盤は「データを正しい場所に届けるパイプライン」でしたが、今回はその中にインテリジェンスを注入し、出口側にエージェントを待機させるアーキテクチャへの転換を示していたと思います。
Pub/Sub AI Inference SMT(GA)
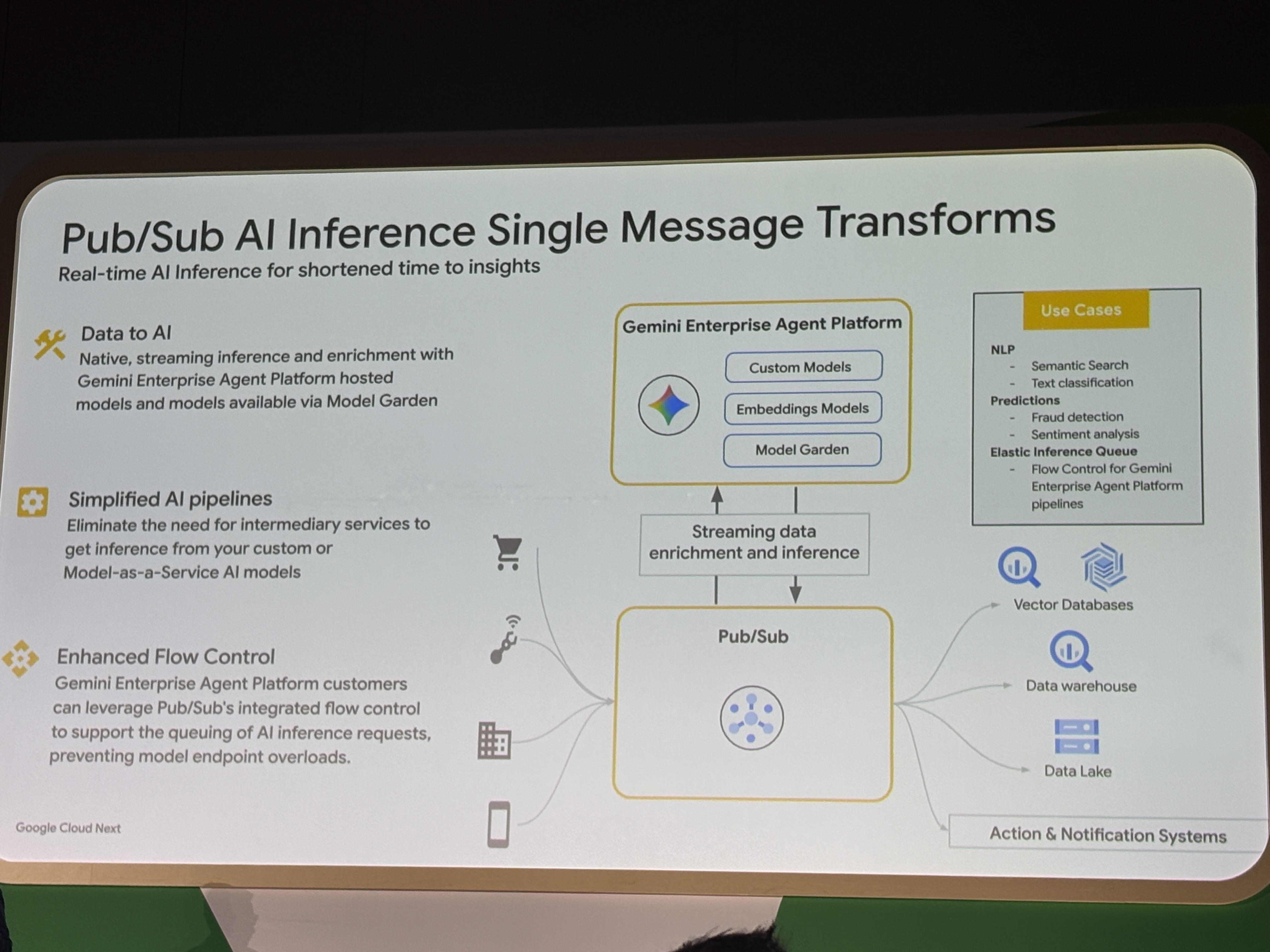
セッション最初の大きな発表がPub/Sub AI Inference Single Message Transforms(SMT)です。
Pub/Subのストリーミングパスの中で直接モデルを呼び出すことができます。Gemini Enterprise Agent Platform(このイベントでGA)上のモデルやModel Gardenのモデル、カスタムモデルのいずれにも対応しており、間にサービスを挟む必要がないという点が特徴となっています。
そのためフロー制御もPub/Sub側で統合管理されるため、モデルエンドポイントの過負荷を心配せずに済みますね。
ユースケースとして3点が挙げられます。
- NLP(セマンティック検索、テキスト分類のためのエンベディング生成)
- 予測(不正検知、センチメント分析)
- Elastic Inference Queue
Pub/SubをAIワークロードのフルマネージドキューとして使い、安定したパフォーマンスを得るために使用するというユースケースですね。
従来の方法だとPub/Subからメッセージを受け取った後にCloud Runなどで推論APIを呼び出し、結果をまた別のトピックにpublishするという中間サービスが必要でした。
SMTではこれらの仲介が不要となり、かつ管理コンポーネントが1つ減ってレイテンシも短くなるのはシンプルに嬉しいポイントですね。
Pub/Sub Bigtable Subscriptions(Preview)

Pub/SubトピックからBigtableテーブルへ直接書き込む新しいサブスクリプションタイプがPreviewで発表されました。カスタムETLもDataflowも不要となるので、スケーリング・エラーハンドリング・フロー制御はPub/Subが全部管理します。
BigQuery・Cloud StorageはこれまでPub/Subのサブスクリプション先としてありましたが、これに続く3つ目のネイティブなサブスクリプション先になります。
特にBigtableのサブミリ秒レイテンシが必要なリアルタイムサービングのユースケースにおいては、Dataflowを間に挟まずに済むのは運用負荷低減やレイテンシの削減に大いに役に立つものだと思います。
リアルタイム処理エンジンとしてのBigQuery
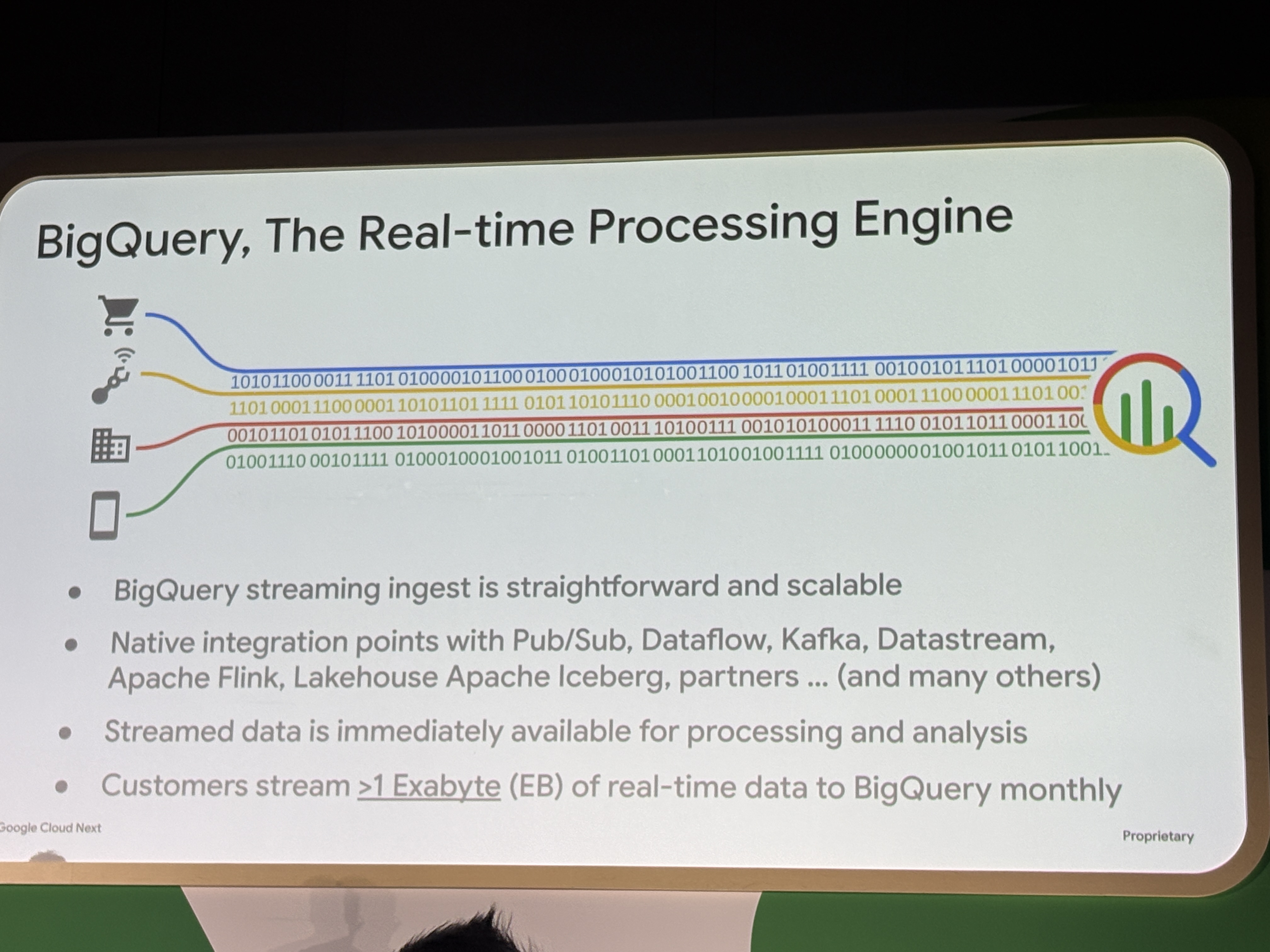
「BigQueryはデータウェアハウスだと思っているかもしれないが、実はストリーミング処理エンジンでもある」という切り出しから説明がありました。
Continuous Queryのユースケース

BigQuery Continuous Queryが対象とするユースケースが4つ紹介されました。
- Continuous Analytical Processing:SQLでストリーミングデータに対する無制限のサーバーレス分析。リアルタイムダッシュボード、エンティティ抽出、イベント分析。対象はデータアナリスト。
- Generative AI for real-time app dev:AI+MLパイプラインの自動化。リアルタイムパーソナライゼーション、動的コンテンツ生成。対象はアプリケーションエンジニア。
- Real-time reverse ETL:BigQueryからPub/Sub・Spanner・Bigtableへのデータ変換・レプリケーション。対象はデータエンジニア。
- Agentic AI:リアルタイムデータを使ったエージェントワークフロー。エージェントの再訓練やモニタリング。対象はAIプラクティショナー。
Stateful Data Processing(Preview)

これまでContinuous Queryはステートレスで、レコードを1件ずつ独立に処理するだけでした。それが今回のPreview公開された機能でステートフル処理に対応しました。
SUM・AVG・APPROX_COUNT_DISTINCTなどの集約関数、タンブリングウィンドウ、ストリーム同士のINNER JOIN、そしてUpdates/Deletesの処理(CHANGES TVF経由でPub/Subシンクへ出力)が使えるようになったとのことです。
ステートフル処理が加わったことで、BigQuery CQはFlinkやSpark Structured Streamingが担っていた領域にSQLだけで入れるようになりました。
Dataflowによる複合リアルタイム処理
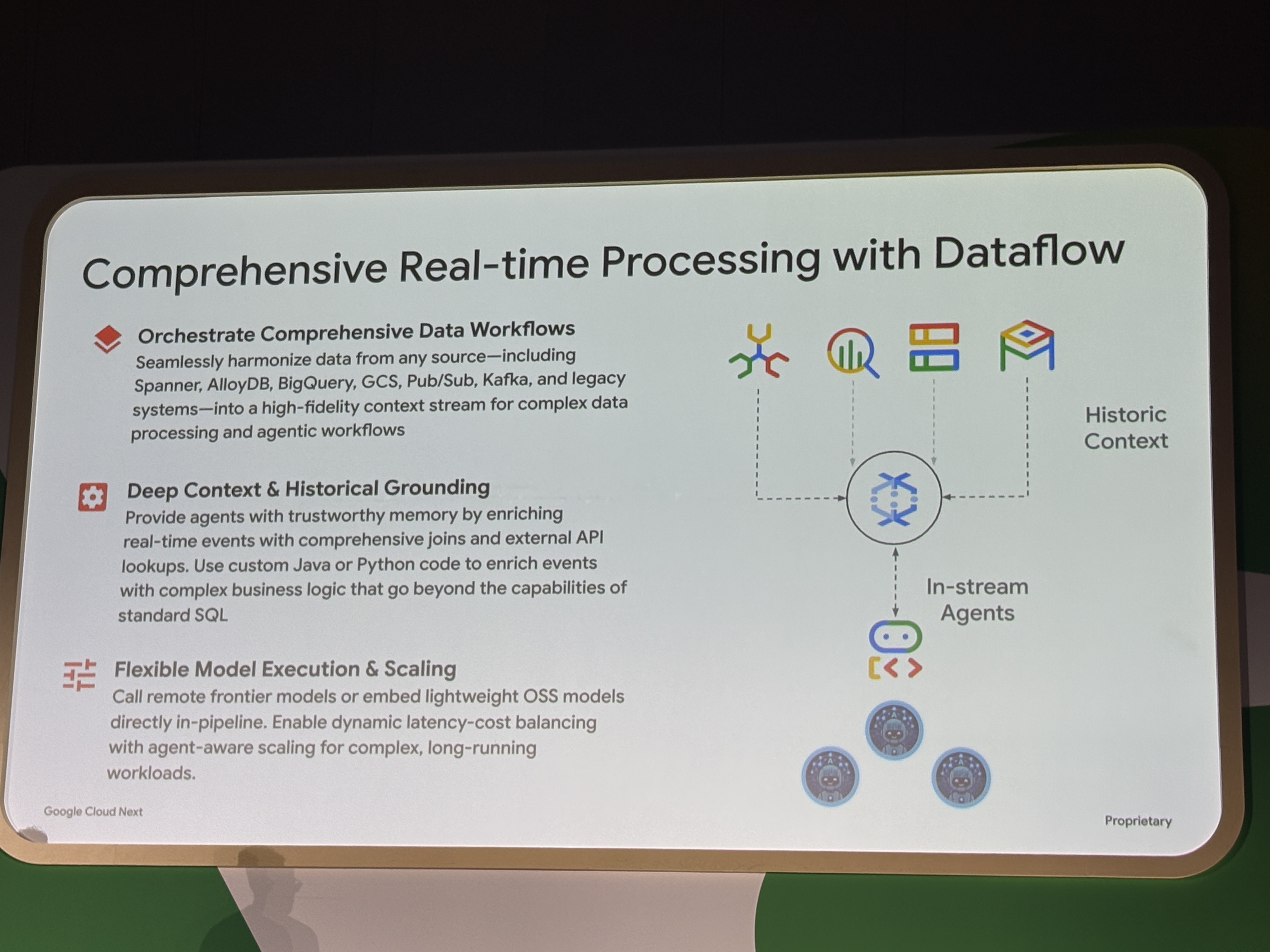
前述したPub/Sub SMTやBigQuery CQで処理しきれない複雑なケースももちろん存在しています。複雑なリアルタイム処理が必要な場合はDataflowを使うことで、SpannerやAlloyDB、BigQuery、GCS、Pub/Sub、Kafkaといったデータソースと統合し、プログラマティックに制御をしていくことが可能になります。
内部的にはIn-stream AgentsというエージェントがカスタムAIモデルをパイプライン内で直接実行して、ストリーム内でリアルタイムに判断を下しています。
セッション全体を振り返って
このセッションで感じたのは、Google Cloudのストリーミング基盤がただの「データ転送用のパイプライン」から「エージェントへの伝達パイプライン」へと役割を変えつつあるということです。
他のセッションでもAIエージェントファーストで様々な機能のアップデートが入っていましたが、ストリーミング領域においてもPub/Sub AI SMTでストリーム上に推論を埋め込んだり、BigQuery CQでステートフルな分析を加えたりなど、インテリジェンスを付与するためのアップデートがありました。
Pub/Sub SMT・BigQuery CQ・Dataflowの3つは「どれを使えばいいのか」が迷うところですが、1メッセージ単位の推論ならSMT、SQLで書ける集約・結合ならBigQuery CQ、複数ソースの統合やカスタムロジックが要るならDataflowという棲み分けと理解しました。
今回は記事が長くなってしまうので入れていませんが、Anthropicの事例も個人的にかなり面白かったのでアーカイブが出たらぜひご視聴ください!




