
こんにちは、DX開発事業部の山中です。Google Cloud Next ’26 に現地参加してました!
この記事は、Google Cloud Next ’26 ライブストリーム「Nano Banana, Veo, and Lyria: Mastering the Google gen media stack」のセッションレポートです。動画: YouTube
ホストの Stephanie Wong さん(Google Cloud)が、Product Marketing Manager, Gen Media の Khulan Davaajav さん(Google Cloud)に、「Work From Home」と題したショートフィルムを題材に、Nano Banana(画像)・Veo 3.1 Lite(動画)・Lyria 3 Pro(音楽)・Gemini 3.1 Flash TTS(音声)・Gemini 3.1 Flash Live with Live Avatar という Gen Media スタック全体の使い分けを一気通貫で解説されたトーク番組形式のセッションでした。

こんな方におすすめ
- 生成 AI で画像・動画・音楽・音声を扱う「Gen Media」の全体像を押さえたい方
- Nano Banana・Veo・Lyria・Gemini Audio の使い分けと、それぞれのプロンプト設計の実例を見たい方
- 「AI で映像制作」の現実解として、どのモデルをどこで繋ぐかを知りたい方
登壇者
- Stephanie Wong さん(Host, Google Cloud)
- Khulan Davaajav さん(Product Marketing Manager, Gen Media, Google Cloud)
そもそも Gen Media とは何か
Gen Media は以下 4 つのモデル群をまとめた総称です。
| モデル | 役割 |
|---|---|
| Nano Banana | 画像生成・編集 |
| Veo | 動画生成 |
| Gemini Audio | 文字起こし、テキスト読み上げ(TTS) |
| Lyria | 音楽生成 |
それぞれが毎週・隔週単位でアップデートされている領域とのことで、Gen Media と聞いたら「Creative AI のこと」と捉えれば良い、という整理でした。セッション本編は、この 4 モデルを全部使って 1 本のショートフィルムを作るデモを軸に進みます。
個人的には、Vertex AI の上で動く「AI for developers」と「AI for creators」を分けて捉える整理が分かりやすく、Gen Media は後者の総称だと思って読み進めると頭に入りやすいです。
題材:Work From Home ショートフィルム
Khulan さんが作られたデモは、「在宅勤務でついスナックを食べすぎてしまう」という自身の体験をもとにしたミニストーリーです。
- 朝 9 時「ひとつだけジェリービーンを食べよう」と自分に言い聞かせる
- 日中、知らないうちに大量のスナックを消費
- 夕方 5 時、謎の糖分パワーで夜を駆け抜ける
- その後、避けられない「シュガークラッシュ」で倒れる
- 翌日、また同じことを繰り返す
3D レンダー風のまろやかなビジュアルで、キャラクターがキッチンで PC を開き、ラジオをつけて踊り、ディスコパーティー風に盛り上がったあとソファでぐったりする──という 1 分ほどのコミカルな映像でした。

この 1 本を、以下の流れで組み立てていきます。
- Nano Banana でストーリーボードになる高精細な静止画を作る
- Veo 3.1 Lite で静止画をアニメーション化する
- Lyria 3 Pro で時間軸に合わせた BGM を作る
- Gemini 3.1 Flash TTS でナレーションを付ける
- 全体を繋いで完成
以降、各ステップを見ていきます。
Nano Banana:「どのカメラで撮ったか」までプロンプトで指示する
まず Nano Banana でストーリーボードの静止画を作るパートです。Khulan さんがスクリーン上で見せてくれたプロンプトが、想像していたよりずっとカメラ寄りでした。
3D render, Memphis Design style, smooth soft-touch silicone textures, bulbous rounded geometry, solid color-blocking. Shot on vintage 35mm film, CineStill 800T, heavy halation on glossy highlights, Black Pro-Mist filter, warm cinematic studio lighting.
ポイントは 2 つあるとのことでした。
- 被写体のテクスチャ指定: 「3D レンダー、シリコン調のソフトタッチ、丸みのあるジオメトリ、色はソリッドなブロッキング」
- カメラ・撮影条件の指定: 「35mm フィルム、CineStill 800T(フィルムの種類)、ハレーション強め、Black Pro-Mist フィルター、暖色系のシネマ照明」
「どんなカメラで撮ったか、どんなレンズで撮ったか」まで突っ込める点は、クリエイターから特に好評だと紹介されていました。

プロンプトは Gemini に蒸留してもらう
「そこまで細かいカメラ用語、自分で思いつかない」と Stephanie さんが率直に聞くと、Khulan さんの回答はシンプルでした。
- Behance や Instagram などで参考になるビジュアルを大量に眺める
- 気に入った画像を Gemini アプリに渡して「この画像の撮影スタイル・ライティング・写真用語を抽出して」と依頼する
- 出てきた語彙を Nano Banana のプロンプトに流し込む
参考画像を集めるところだけ人間の仕事で、スタイル記述の言語化は Gemini にやらせる、という分業です。「AI を使えるところは素直に AI に任せる」という話で、確かにこれは実務に持ち込みやすいと感じました。

Veo 3.1 Lite:Lite が軽いとは限らない
続いて、Nano Banana で作った静止画を Veo 3.1 Lite で動かすパートです。Veo 3.1 Lite は数週間前にリリースされたばかりのモデルで、以下の点が強調されていました。
- 市場でもっともコスト効率が良い部類の動画モデル
- 品質は上位モデルに近い水準(Lite だからといって画質が犠牲になっているわけではない)
- 生成速度が速く、多くのフレームが 60 秒未満で生成できた
キャンペーン動画のようにフレーム数が多くなるユースケースでは、コストと速度が実用性を大きく左右するため、Lite は有力な選択肢になりそうです。
First Frame / Last Frame でアニメーションを制御する
デモで面白かったのが、First Frame(最初のコマ)と Last Frame(最後のコマ)の 2 枚を静止画で渡し、あいだの動きを Veo に埋めさせるやり方です。
- 上段: Nano Banana で作った「first frame」と「last frame」の 2 枚
- 下段: それを Veo 3.1 Lite が補完して作った動画
プロンプトの例として紹介されていたのが「Make the bottom six appear like a puff or like a magic.」のような指示でした。Khulan さんは「正直なんとなく打ったら、puff(ふわっと現れる)の意図をモデル側がちゃんと汲んでくれた」とおっしゃっていました。ラジオをつけて踊るシーンでは、「踊り終わりの姿勢」を last frame として指定したら、その姿勢にきれいに着地して終わった、という例も見せてくれました。

First Frame だけでも十分動く
始点だけ決めたいケースでは、Last Frame を省略できます。以下の画面では Last frame が「none」になっていて、First frame として画像を 1 枚渡し、「Pan the camera around the character.」と指示するだけで、キャラクターの周りをカメラが回り込む映像が生成されていました。

開発者向けのヒント:UI に「カメラ操作」を埋め込む
Khulan さんが開発者向けに話されていたアドバイスが、そのまま使える内容でした。クリエイターのプロンプトには「dolly zoom」「camera panning」といったカメラワーク用語が頻出するため、アプリ側でそれを機能化してしまう、という発想です。
「毎回ユーザーにカメラワークの単語を入力させるのではなく、『360 度パン』のようなボタンとしてアプリに組み込み、裏でプロンプトに差し込んでしまえばいい」
Veo 3.1 Lite を呼び出すアプリを作るなら、UI に「被写体を回る」「ドリーズーム」などのボタンを並べ、クリックで対応するプロンプト片を自動付与する設計が効く、ということです。
動画内の効果音も Veo 3.1 Lite で賄える
もうひとつ刺さったのが、効果音の扱いです。デモ動画の「あくび」「ラジオを付けるガチャッという音」などの効果音は、すべて Veo 3.1 Lite が動画と一緒に生成しているとのことでした。
「SE を別途探して貼る必要がない。モデルが映像とセットで出してくれる」
動画モデルが動画と音を一体で生成できる世界になると、後工程で大きく手間が減ります。素材探しの時間がごっそり減る印象です。
Lyria 3 Pro:タイムスタンプで音楽の構成を指揮する
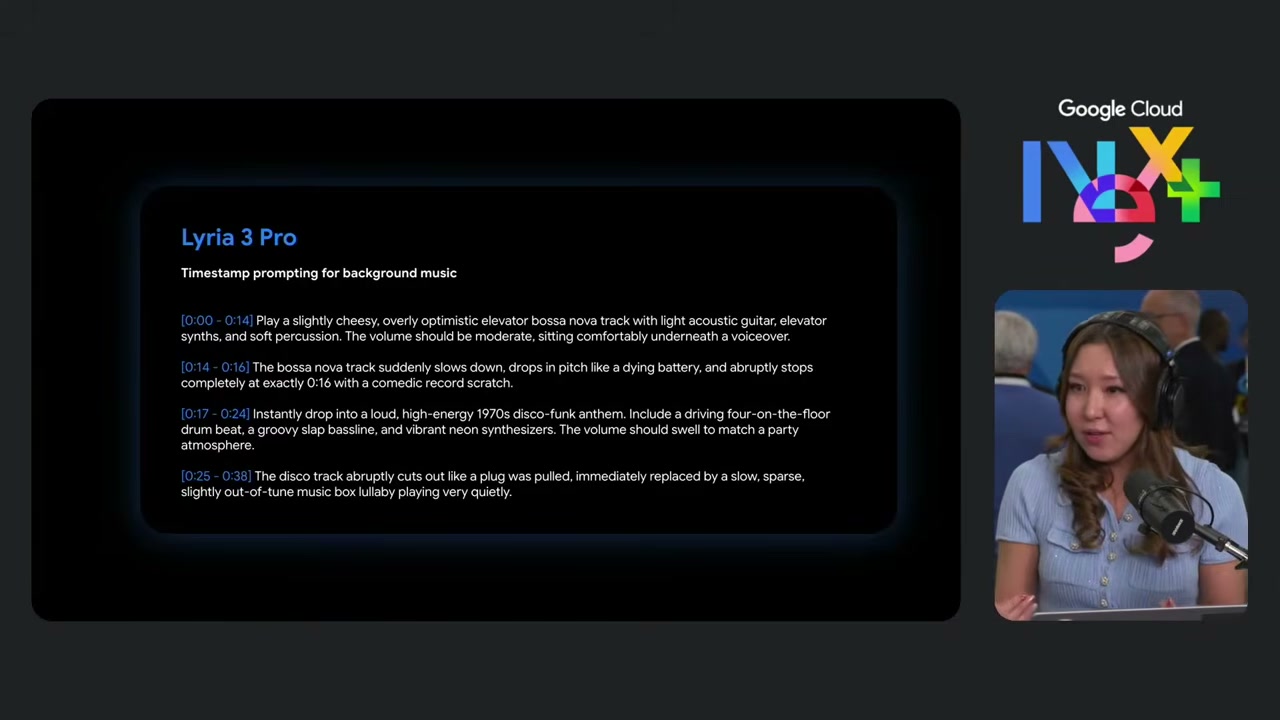
BGM を担当するのが Lyria 3 Pro です。Stephanie さんから「動画のシーン切り替え(9 時の落ち着いた雰囲気 → 5 時のディスコパーティー)に合わせて曲が切り替わっていたのが印象的だったが、どうやって合わせた?」と振られて出てきたのが、タイムスタンプを使ったプロンプトでした。
[0:00 - 0:14] Play a slightly cheesy, overly optimistic elevator bossa nova track with light acoustic guitar, elevator synths, and soft percussion. The volume should be moderate, sitting comfortably underneath a voiceover. [0:14 - 0:16] The bossa nova track suddenly slows down, drops in pitch like a dying battery, and abruptly stops completely at exactly 0:16 with a comedic record scratch. [0:17 - 0:24] Instantly drop into a loud, high-energy 1970s disco-funk anthem. Include a driving four-on-the-floor drum beat, a groovy slap bassline, and vibrant neon synthesizers. The volume should swell to match a party atmosphere. [0:25 - 0:38] The disco track abruptly cuts out like a plug was pulled, immediately replaced by a slow, sparse, slightly out-of-tune music box lullaby playing very quietly.
指定できる粒度が細かくて驚きました。
- 冒頭 14 秒は「軽めのボサノヴァ」でナレーションを邪魔しない音量
- 14〜16 秒で「電池切れのようにピッチが下がって、レコードスクラッチで終わる」
- 17〜24 秒で「1970 年代ディスコファンクに即切り替え」
- 25 秒以降は「プラグを抜かれたようにブツ切りになり、オルゴールの子守唄に」
Lyria 3 Pro はボーカル入りも生成できますが、今回のデモではボーカルに気を取られないよう、あえてインストゥルメンタルだけに絞ったとのことでした。
プロンプトも Gemini に書いてもらう
興味深かったのが、このプロンプト自体を Khulan さんが手書きしていない点です。ワークフローは次の順番だったとのこと。
- 出来上がった動画を Gemini に渡す
- 「Lyria 3 Pro 向けに、動画の展開に合わせた BGM プロンプトを書いてほしい。コメディ調で楽しげに」と依頼する
- Gemini が動画をフレーム単位で理解し、タイムスタンプ付きプロンプトを出力
- それをそのまま Lyria 3 Pro に渡す
「キャラクターが眠ったシーン=子守唄」という文脈を、Gemini のマルチモーダル理解が勝手に拾ってくれるとのことでした。BGM を 1 曲ずつ探してつなぎ合わせていた時代からすると、かなり違う作り方になっている印象です。
Gemini 3.1 Flash TTS:200 種類の表現タグで「棒読み」から脱却
セッションで Khulan さんが「一番好きなローンチ」と断言されていたのが、前週リリースされた Gemini 3.1 Flash の TTS(Text-to-Speech)機能です。
特徴は 200 以上の expressiveness tag(表現タグ) で、ナレーションの感情や息遣いを細かく指示できる点です。タグは角括弧([ ])で囲んで文中に埋め込みます。
[positive] This is the greatest mystery of working from home. At nine AM, you tell yourself: just one jelly bean. [panicked] But as time passes, you get exhausted and snack, not even realizing how much you've eaten. [anticipation] Then, five PM hits, and a miracle happens. [excitement] You shut down the laptop, and suddenly this hidden store of energy is powering you for the night! [tiredness] But then you crash. The inevitable sugar crash. [optimism] But hey, you can't beat the commute. This is the glamour of working from home, and we'll most likely do it all again tomorrow. [laughs].
[positive]/[panicked]/[anticipation]/[excitement]/[tiredness]/[optimism]といった感情タグのような「間」を表すタグ[laughs]のような効果音タグ
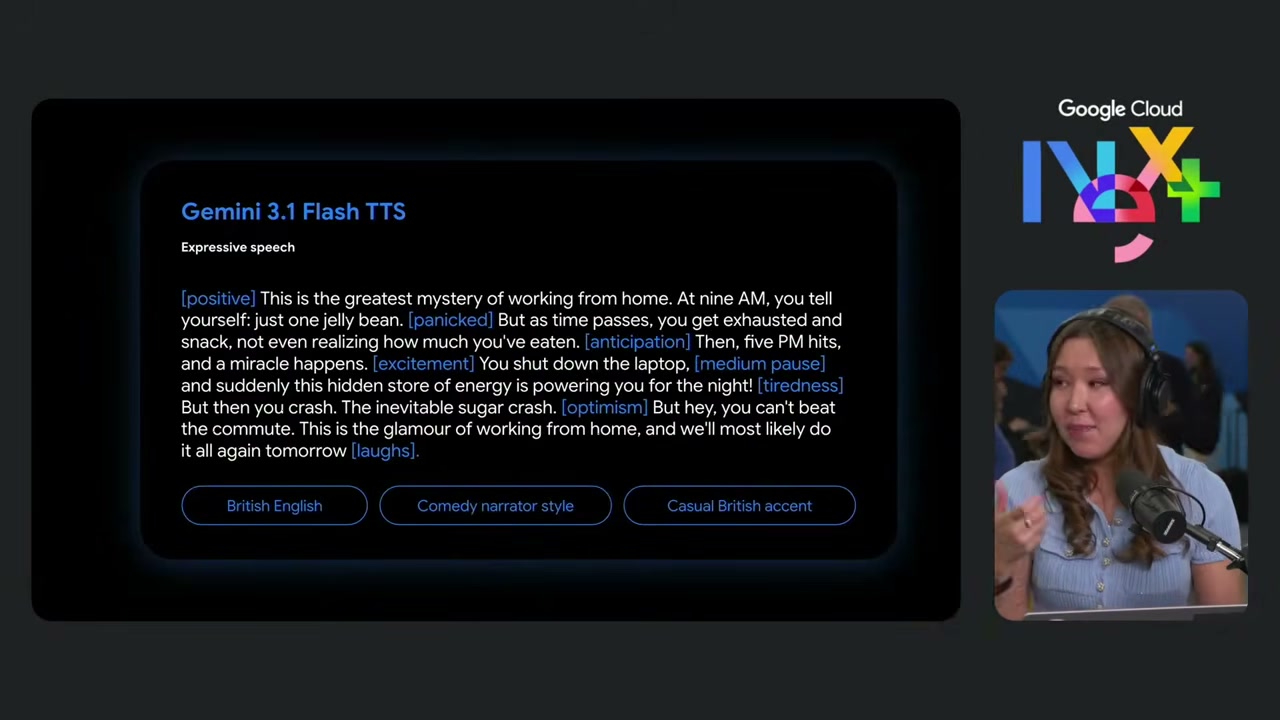
さらに、声そのもののスタイルも指示できます。画面下に並んでいたボタンが、その設定値でした。
- British English(英語のバリエーション)
- Comedy narrator style(ナレーションのスタイル)
- Casual British accent(訛りとフォーマリティ)
デフォルトだと「Queen’s English」のような格式張った声になってしまうので、今回のコメディ調の動画に合わせて「カジュアルなブリティッシュ訛り」に寄せた、とのことでした。
Khulan さんは「200 個のタグを Gemini に渡して、動画に合うタグ付きスクリプトを書いてもらった」ともおっしゃっていて、ここでもプロンプト生成は Gemini に任せていました。
オーディオブック自動化というユースケース
同僚の方が作られたデモも紹介されました。200 ページ規模のオーディオブック原稿に対して、Gemini 3.1 Flash Light が ページ単位でタグを自動付与する というワークフローだそうです。表現タグを 1 ページずつ手で付けていたら現実的ではない規模なので、タグ付け自体を LLM に回す発想は自然だと感じました。
モノトーンな AI ナレーションの時代から、ここまで制御できるようになると、単純な読み上げから「声の演出」まで踏み込めるようになります。
Live Avatar:Gen Media の次の一手
セッションの最後で、この日プレビュー公開されたばかりという Gemini 3.1 Flash Live with Live Avatar のデモが始まりました。
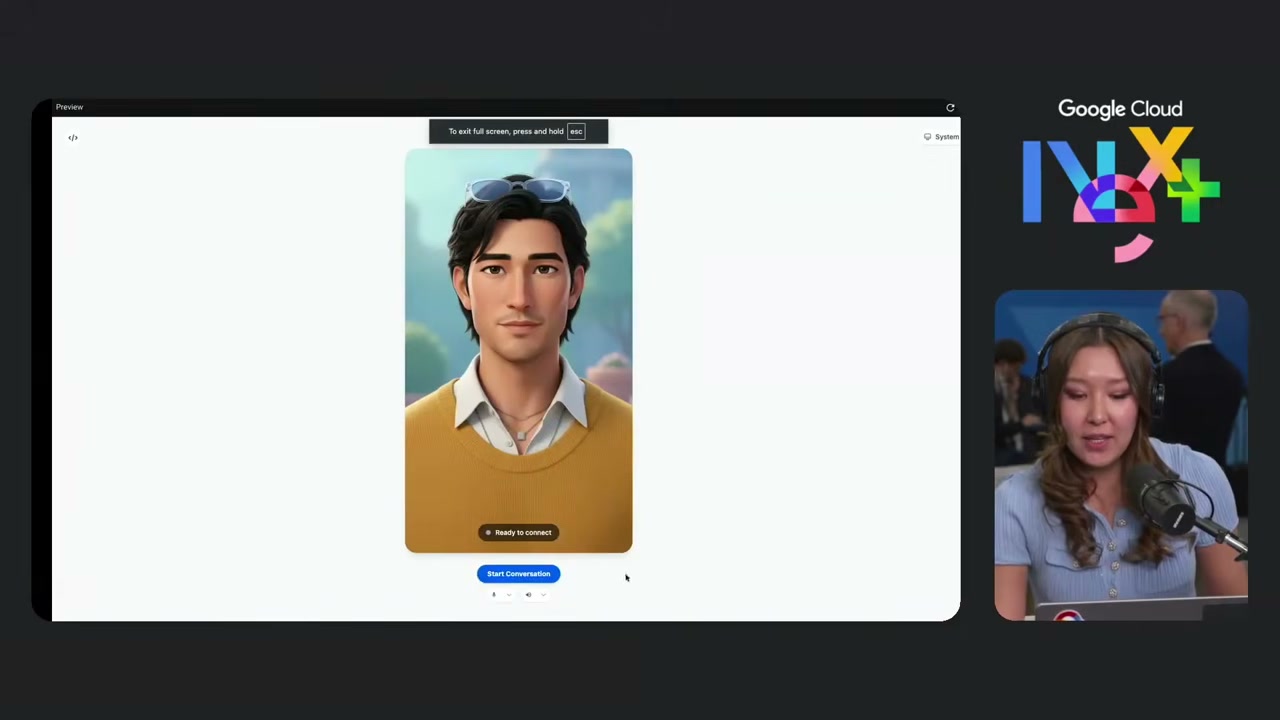
従来の AI アバターと大きく違うのが、audio-to-audio のリアルタイム対話 であり、かつ Google Search に接続してライブデータを返せる という点です。静的な動画アバターではなく、その場で喋って返してくれるモデルです。
Stephanie さんが「今のラスベガスの天気は?」と画面内のアバターに話しかけると、アバターが口パクを合わせながら「最高 78°F、最低 56°F、日中は晴れ、夜は快晴。何か予定があるの?」と答える、というやり取りが会場で実演されました。Google Search から引いてきたその日のラスベガスの気温データが、リップシンクと一緒に返ってくる挙動です。
会場は少し賑やかで、Stephanie さんが笑いながら「I need to scream louder(もっと大声じゃないと伝わらないかも笑)」と声を張るひと幕もありました。ライブでこの手のデモが一発で通るのは気持ちがいいです。
用途として Khulan さんが挙げていたのが以下でした。
- 教育・学習: 本を読む代わりに、アバターと会話しながら学ぶ
- トレーニング: ロールプレイ的な研修
- ライブ配信: そのまま対話型コンテンツに出す
アバターは事前構築された複数のスタイルから選べて、声も差し替え可能とのことです。「裏は複数モデルの積み重ねだが、API 的には一枚に抽象化されている」という設計方針が印象に残りました。リップシンクの精度もデモで見る限り違和感がなく、ここは数ヶ月で大きく進化した部分だと思います。
これからの Gen Media:ワールドモデルと「フロー状態」
セッションの後半、Khulan さんが「今、クリエイターとして一番ワクワクしているのは?」という問いに答えた内容が、Gen Media の次の方向性を示していて面白かったです。
1. ワールドモデル(World Models)
Google の Genie 3 に代表されるワールドモデル(シミュレートされた 3D 世界を生成する AI)が、クリエイターの役割を「フレームを 1 枚ずつ作る人」から「生成された世界の中を歩き回る カメラマン」に変える、という話でした。
- 現状: 画像・動画を 1 アセットずつ生成し、つなぎ合わせる
- 次: AI が生成した「世界」の中に入り、自分がカメラを持って動きながら撮る
ロボティクスでの活用も大きいですが、クリエイティブ領域でも、フレーム単位の操作から「世界の中を歩く」発想への移行があり得る、という整理でした。Genie 3 はまだ Google Cloud には載っていないとのことで、今後の展開待ちです。
2. フロー状態(Flow State)を守る = レイテンシ削減
もうひとつが、生成のレイテンシを下げる方向性です。クリエイターが没頭している状態(フロー状態)で 2 分待たされると、その場で集中が切れてしまう、という話でした。モデルの画質・機能だけでなく、生成時間を短くすることが作業体験そのものの価値を決める という視点で、Gen Media 領域の次の優先事項として挙げられていました。

「画質 vs 速度」のトレードオフはしばらく残ると思いますが、クリエイターが主役である以上、速度側の優先度がいまよりも上がっていく、という見立ては納得感がありました。
まとめ
- Nano Banana: カメラ・レンズ・フィルム・フィルターまでプロンプトで指示できる。スタイル記述は参考画像を Gemini に渡して抽出するのが実用的
- Veo 3.1 Lite: コスト効率が良く、生成も 60 秒未満で終わる。First Frame / Last Frame で始点と終点を握り、途中を Veo に任せる。効果音も同じモデルで出せる
- Lyria 3 Pro: タイムスタンプ付きプロンプトで BGM の構成を秒単位で制御。プロンプト自体は Gemini のマルチモーダル理解に書かせる
- Gemini 3.1 Flash TTS: 200 以上の表現タグ(
[positive][panicked]など)で感情・間・声質を指示。オーディオブックのタグ付け自動化のような応用も動いている - Gemini 3.1 Flash Live with Live Avatar: audio-to-audio のリアルタイム対話 + Google Search 接続で、ライブデータを喋るアバター。教育・トレーニング・配信用途
通しで見ると、それぞれのモデルが別々にあるというより、「Gemini に動画を見せて、次のモデル用のプロンプトを書かせる」 という導線で繋がっているのが肝だと感じました。Gen Media は 4 つのモデルをバラバラに覚えるのではなく、「Gemini を中継役にした 1 本のパイプライン」として設計すると、このセッションで紹介されたワークフローがそのまま手元で再現できそうです。
Khulan さんが紹介されていた Gen Media Code Labs(ハンズオン教材)と MCP Servers for Google Cloud Genmedia APIs のリポジトリから触り始めるのが、現時点で一番早い入口だと思います。




