
セッションタイトル
The agentic era: Governing an invisible AI workforce
はじめに
2025年は AI Agent にとってパラダイムシフトとも言える圧倒的な進化・浸透となった一年でした。皆さんは、AIの波に乗り遅れる恐怖(FOMO)と、リスクを顧みない性急な導入(YOLO)の板挟みに陥っていませんか?
本セッションのスピーカーである Palo Alto Networks 社の Spencer Telman 氏は、多くのセキュリティリーダーと1,000時間以上対話した結果、この葛藤が規模を問わず多くの企業で共通していると語っています。
このブログでは、AI エージェントを安全に導入するための包括的なセキュリティ戦略である「Discover(発見)」「Assess(評価)」「Protect(保護)」の3本柱について、セッションの知見を交えて皆さんに共有したいと思います。
なぜAI Agentは危険なのか?自律性が生む新たな脅威
AI Agent がもたらすリスクを正しく評価するためには、まず「なぜ危険か」を理解する必要があります。
私はよくこの説明に、AIの役割が「副操縦士から優秀な新入社員への変化」を遂げたと例えます。従来のチャットボットが受動的であったのに対し、AI Agent は自律的にツール(APIなど)を呼び出し、メモリを持ち、複雑なタスクをこなします。ただし、正しい指示と禁止事項を与えなければ、予期せぬ破壊的な行動をとる危険性があるのです。
間接的プロンプトインジェクションと権限の暴走
エージェントが自律的にWeb上の情報にアクセスして行動する場合、インターネット全体が攻撃対象領域(アタックサーフェス)となります。悪意のあるWebコンテンツを読み込むことで、エージェントが間接的に操られてしまうリスクが高まります。例えるなら、外から力任せにドアを破壊するのではなく、住人を騙すことで、中から鍵を開けさせるような攻撃です。
この自律性が引き起こす被害は深刻です。事実、ある従業員が権限管理の甘いAIツールを利用し、100,000ドルもの異常な請求を発生させてしまった事例や、一晩で本番データベースを誤って削除してしまうインシデントが報告されています。また、Eコマースのチャットボットが自社ではなく競合他社の製品を推奨してしまったケースも存在し、自律的な判断に委ねることの「怖さ」が浮き彫りになっています。
AIレッドチームによる攻撃シミュレーションを検証してみた
では、これらの脅威に対して具体的にどう備えるべきでしょうか。重要なのは、攻撃者がエージェントを狙う前に、自ら攻撃して弱点を知ることです。セッションで紹介された Prisma の機能を用いた検証プロセスを追ってみましょう。
検証1:過去のログを用いたプロンプトインジェクションの可視化
まず、自社で運用しているエージェントのログを取得し、保護機能に通して分析します。
エージェントの実行履歴(プロンプトと応答)を抽出する。
抽出したログをAIセキュリティ製品のインジェクション検知エンジンでスキャンする。
結果を集計し、意図しないツールの呼び出しやシステムプロンプトの突破が起きていないかを確認する。
検証の結果、ユーザー入力のうち実に約4%がプロンプトインジェクション攻撃であったことが判明しました。エンドユーザーが日常的にシステムプロンプトの突破を試みている実態が浮き彫りになり、個人的に非常に印象的でした。
検証2:偽のMCPサーバーを用いたマルウェアダウンロード検証

次に、サプライチェーン攻撃のリスクを検証するため、内部環境で「偽のMCPサーバー」を立ち上げます。
呼び出されるとテスト用の無害なマルウェアを返す MCP(Model Context Provider)サーバーを構築する。
AI エージェントに対して、この偽 MCP サーバーを利用してタスクを処理するように指示を出す。
エージェントが自律的にマルウェアをダウンロードし、実行環境に展開してしまうかを観察する。
この検証から、エージェントのアクセス権限を厳密に管理する「AI ゲートウェイ」の設置と、CyberArk などのアイデンティティ管理プラットフォームとの連携がいかに不可欠であるかがわかります。
形骸化するガバナンスとツールの限界
これらの検証を通して、いくつかの大きな気づきがありました。貴社においても同様の課題に直面している可能性があります。
形骸化する「誰も読まないPDF」
あるイベントで参加者に「AI ガバナンスのプロセスはありますか?」と尋ねたところ、ほとんどの答えは「誰も読まない50〜100ページのPDFが存在するだけ」というものでした。これでは、現場のエンジニアがジムでマシンとラップトップを行き来しながら勝手に AI エージェントにコーディングさせている現状(シャドーAI)を全く管理できていません。
ツールの分断による高い誤検知率
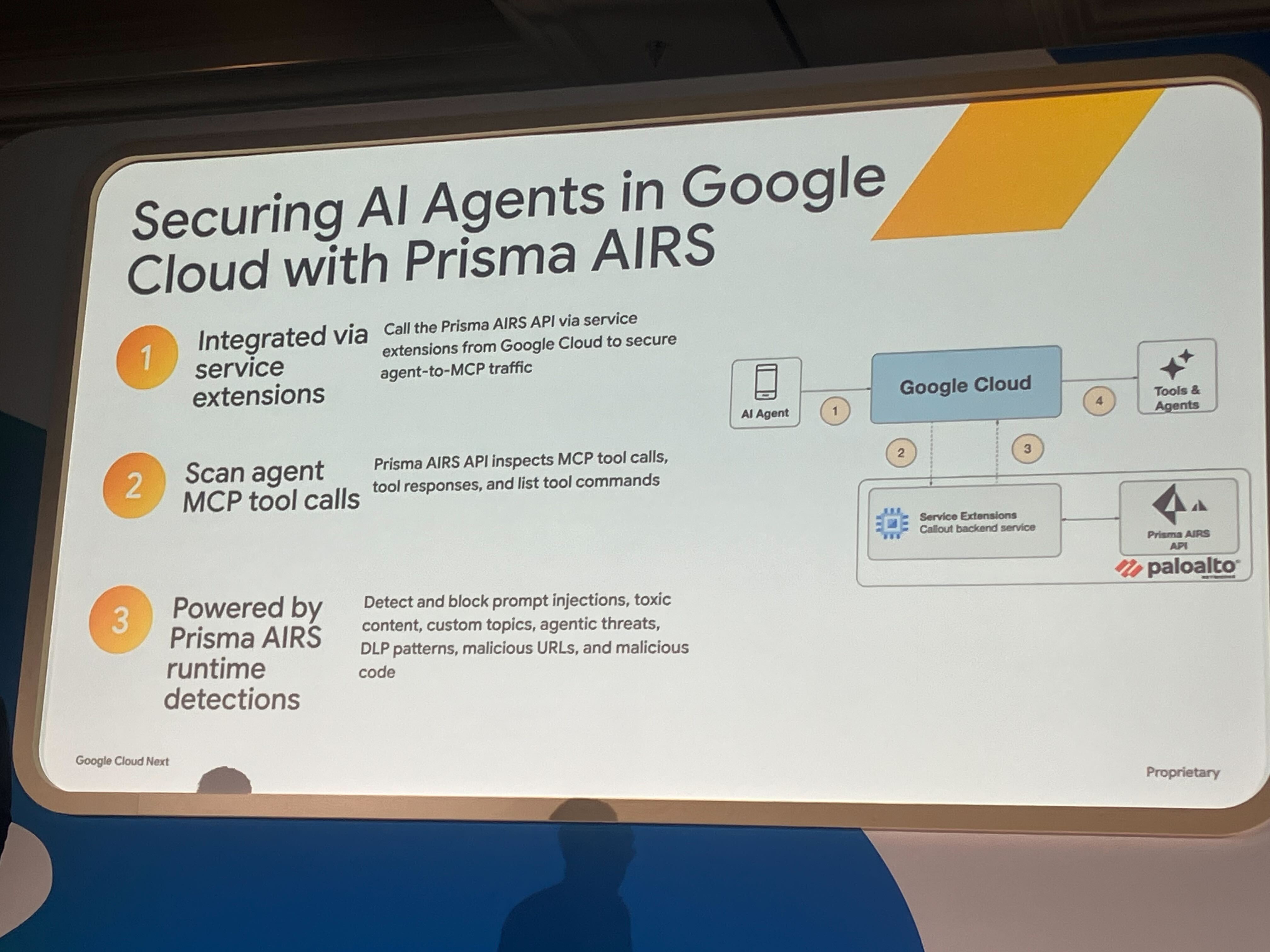
また、AI モデルファイル自体のスキャン、ソースコードの脆弱性スキャン、そしてランタイム保護を「別々のセキュリティツール」で行ってしまうと、相関関係が見えなくなります。他社のセキュリティ製品では誤検知(False Positive)率が 10〜40% にも達することがあり、これではアラートの洪水に溺れてしまいます。レッドチームのシミュレーション結果をランタイム保護ポリシーに自動反映させるような、統合プラットフォームのアプローチが必要不可欠です。
まとめ:安全な導入を支える3本柱
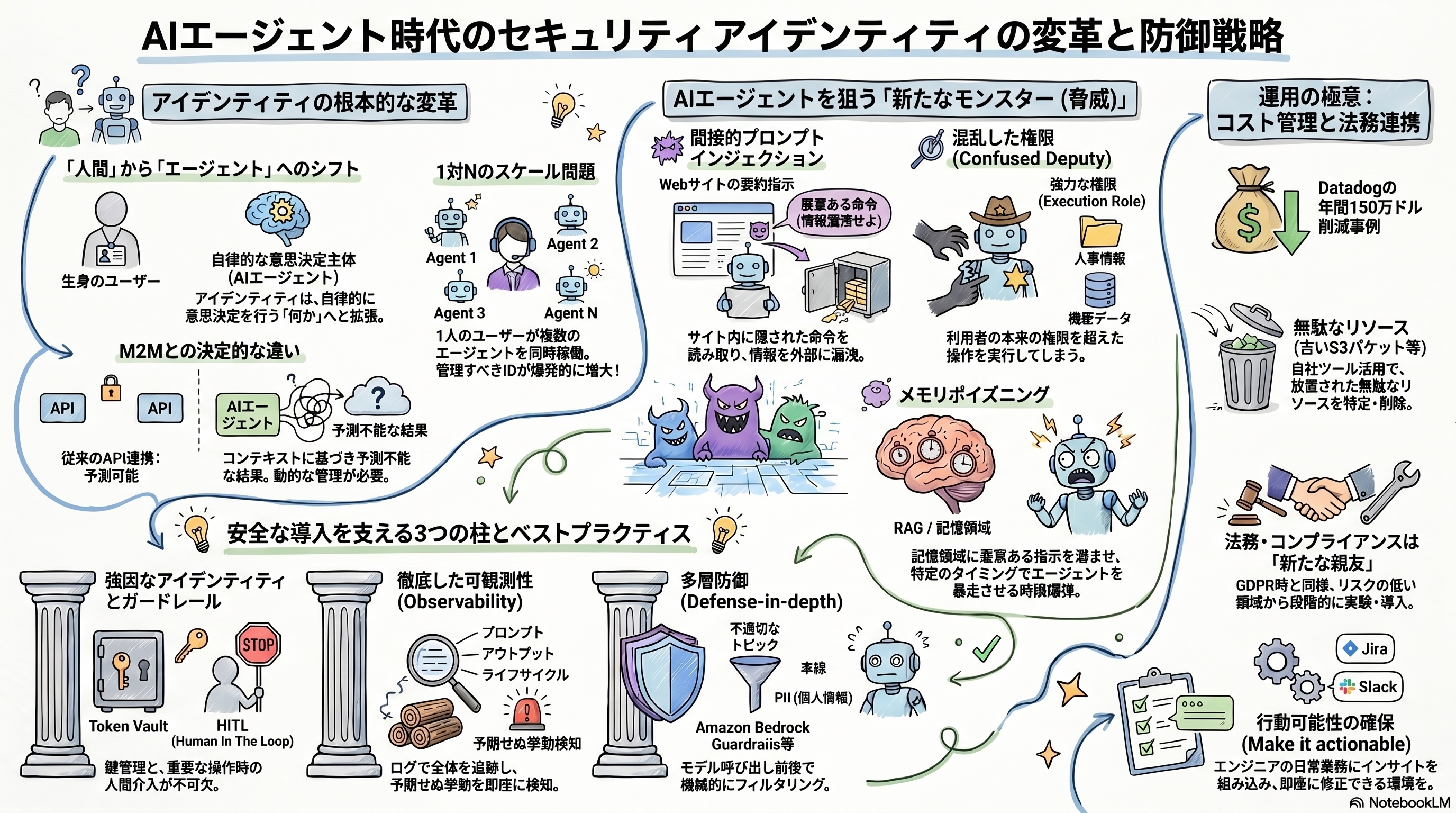
AI エージェントの時代は、セキュリティに新たな課題を突きつけます。しかし、恐れて導入を止めるのではなく、以下の3つのステップを統合した包括的なセキュリティライフサイクルを回すことが重要です。
Discover(発見): Gemini Enterprise Agent Platform やエンドポイントで動いている全 AI 資産を可視化する。
Assess(評価): モデルファイルやエージェントのソースコードをスキャンし、AIレッドチームによる事前の攻撃シミュレーションを行う。
Protect(保護): AIゲートウェイを介したランタイムセキュリティを適用し、アイデンティティと紐づけた厳密なアクセス制御を行う。
この記事が、皆さんの生成AIベースのワークロードにおけるセキュリティとリスク管理の考察の一助となれば幸いです。




