
DX開発事業部の前野佑宜です。
本記事は AWS Summit Japan 2026 Day2(6/26)において実施されたセッション「Agentic RAG が切り開く製造現場語理解の新たな可能性(AIM336)」のセッションレポートです。
セッション概要

本セッションでは、東洋紡株式会社による製造現場へのAI導入事例が紹介されました。同社では「TX(Toyobo Transformation)」として、意識・行動の変革 × 組織風土の変革 × デジタルの力を掛け合わせ、AIを紹介して終わりではなく、現場と一緒に課題を解く取り組みが進められています。
「RAGを入れれば本当に使えるのか?」という問い
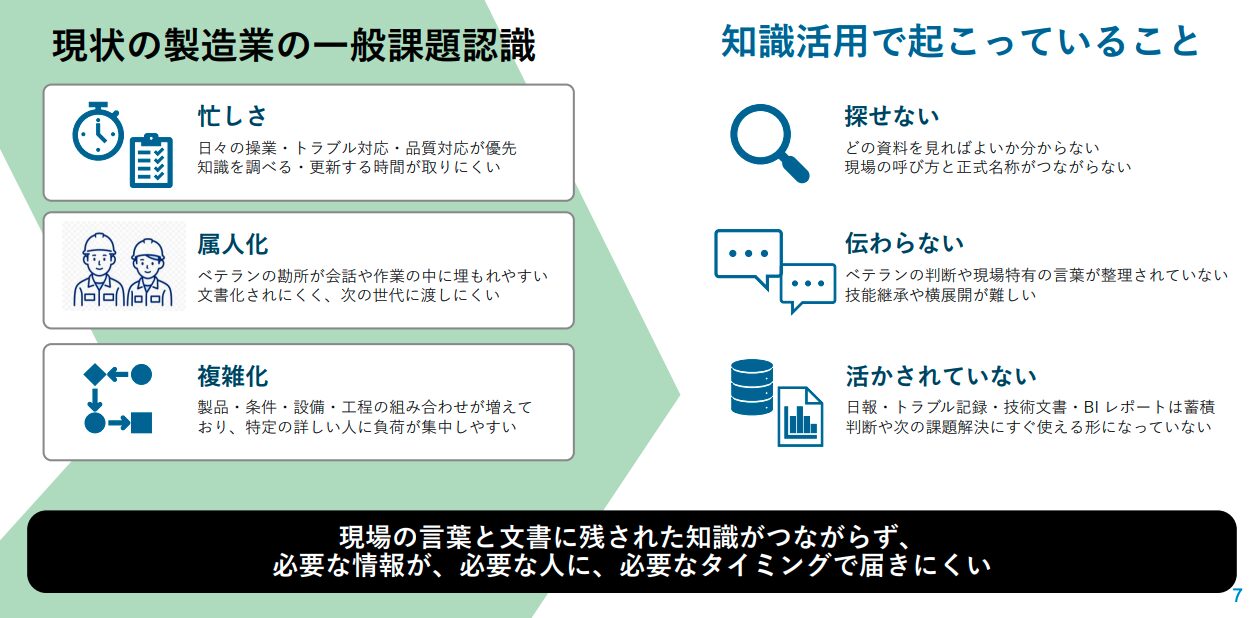
本セッションでは、製造現場で知識活用が難しい構造的な背景として、次の3点が挙げられていました。
- 忙しさ:日々の操業・トラブル対応が優先で、知識を調べる時間が取れない
- 属人化:ベテランの勘所が文書化されにくく次世代に渡しにくい
- 複雑化:製品・条件・設備・工程の組み合わせが増え、特定の人に負荷が集中
結果として「探せない・伝わらない・活かされていない」という状態が常態化しているという課題認識が示されました。
そのうえで、セッションの問いは以下でした。
「生成AI・RAGを入れれば、生産現場の人が本当に知識活用できるのか?」
仮説:RAGを導入するだけでは、現場の期待には届かない可能性がある

現場調査から見えてきたのは「普段の言葉でAIと話したい」というシンプルな要望だったと紹介されていました。

- 普段の呼び方で聞いても通じてほしい(略語・俗称・工場ごとの呼称)
- 一度教えた言葉を次に活かしてほしい
- ざっくりした状況から似た事例を絞ってほしい
- 使っていくうちに現場にフィットしてほしい
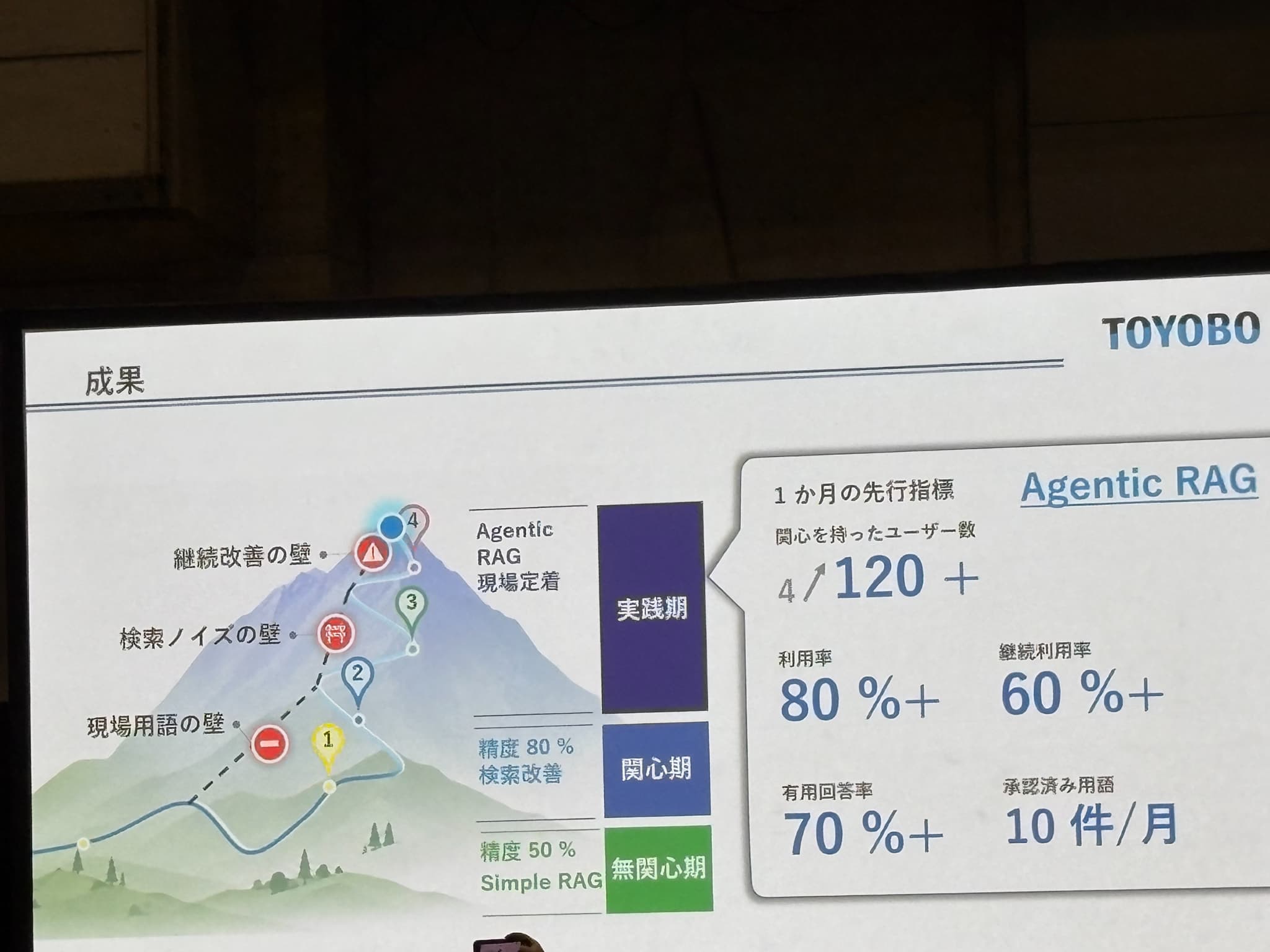
これを踏まえた全体像として「山の登山ルート」に見立てた図が示され、4つの取り組みと3つの壁(現場用語の壁・検索ノイズの壁・継続改善の壁)の対応関係が整理されていました。
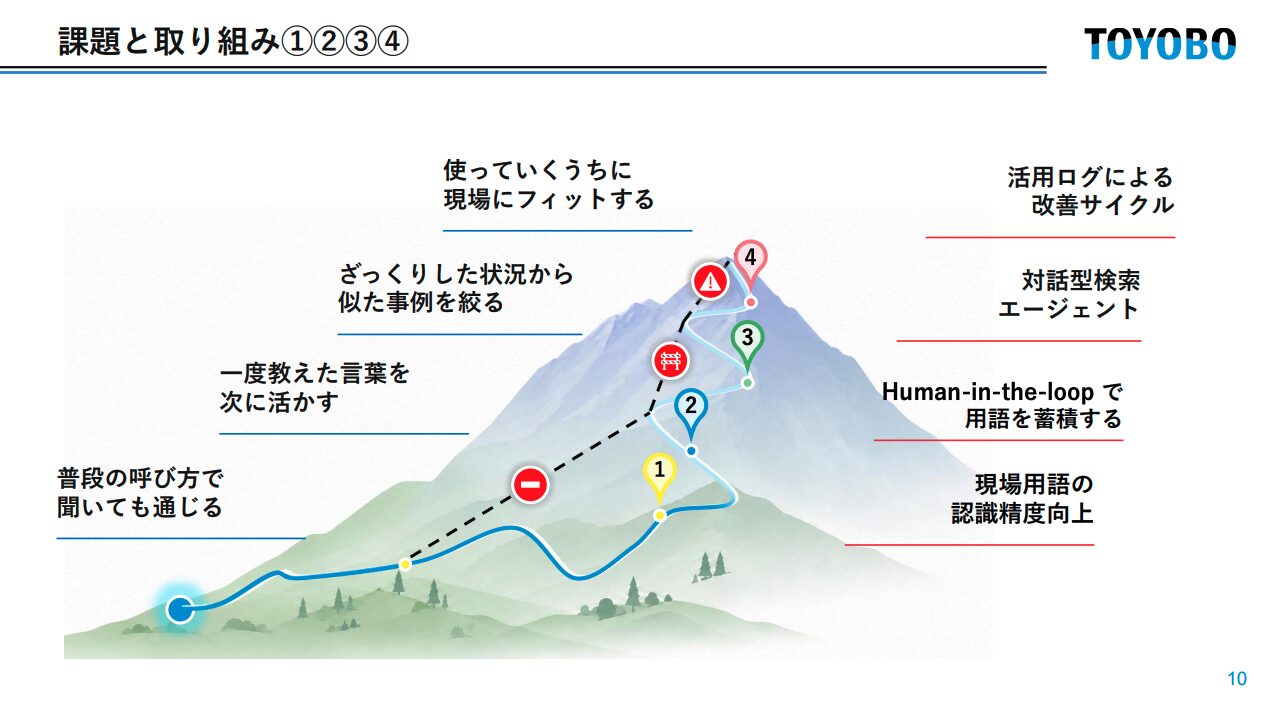
① 現場用語の認識精度を上げる
精度の評価には Amazon Bedrock Evaluations(LLM-as-a-Judge) が活用されました。111問のテストセットに対し、Claude 3.7 Sonnet で Correctness(正確性)を自動採点する手法が紹介されています。
精度50%:現場から「使えない」という声
まず現場用語集を整理し、社内文書を Amazon Bedrock Knowledge Bases に投入した Simple RAG が構築されました。このときの精度は50%。
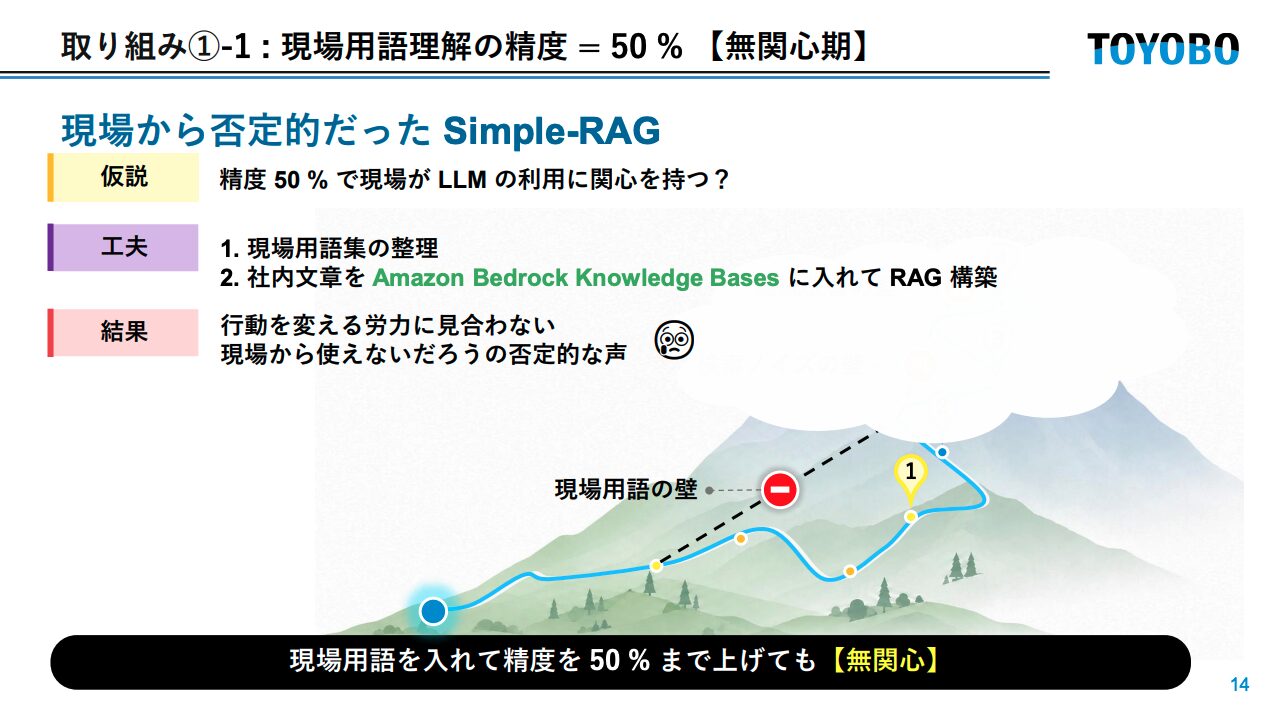
しかし現場からの反応は厳しいものでした。
「行動を変える労力に見合わない」「使えないだろう」
精度50%では、現場の関心を引くことはできませんでした。
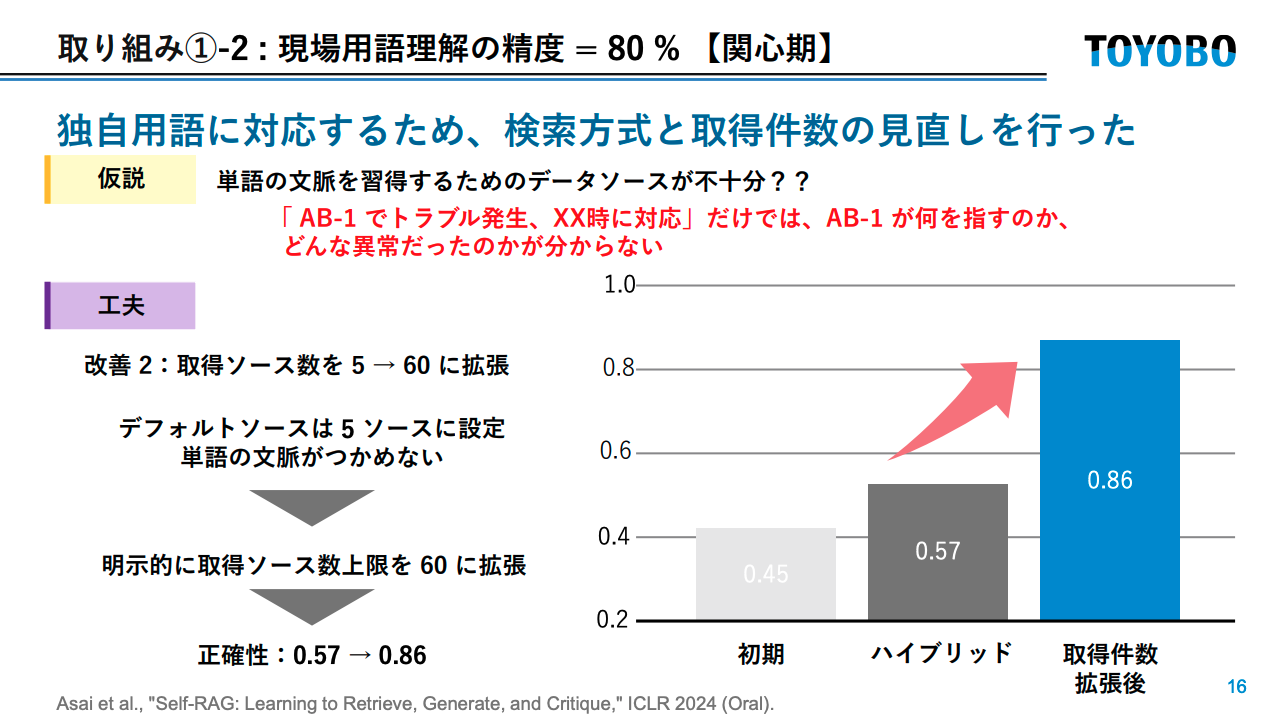
精度80%:現場の態度が変わった
「AB-1」のような数字とアルファベットの組み合わせからなる独自の略語はセマンティック検索が苦手という仮説のもと、2つの改善が実施されました。
| 改善 | 内容 | 正確性スコア |
|---|---|---|
| 初期(Semantic) | デフォルト設定 | 0.45 |
| 改善1:Hybrid検索 | キーワード+セマンティックを明示指定 | 0.57 |
| 改善2:取得件数 5→60 | 単語の文脈をつかむためソース数を拡張 | 0.86 |
精度が上がると、現場の言葉が変わりました。
「結果まで入力すれば良い回答が出てきそうだね。当時どういう現象かの記録も必要だね」
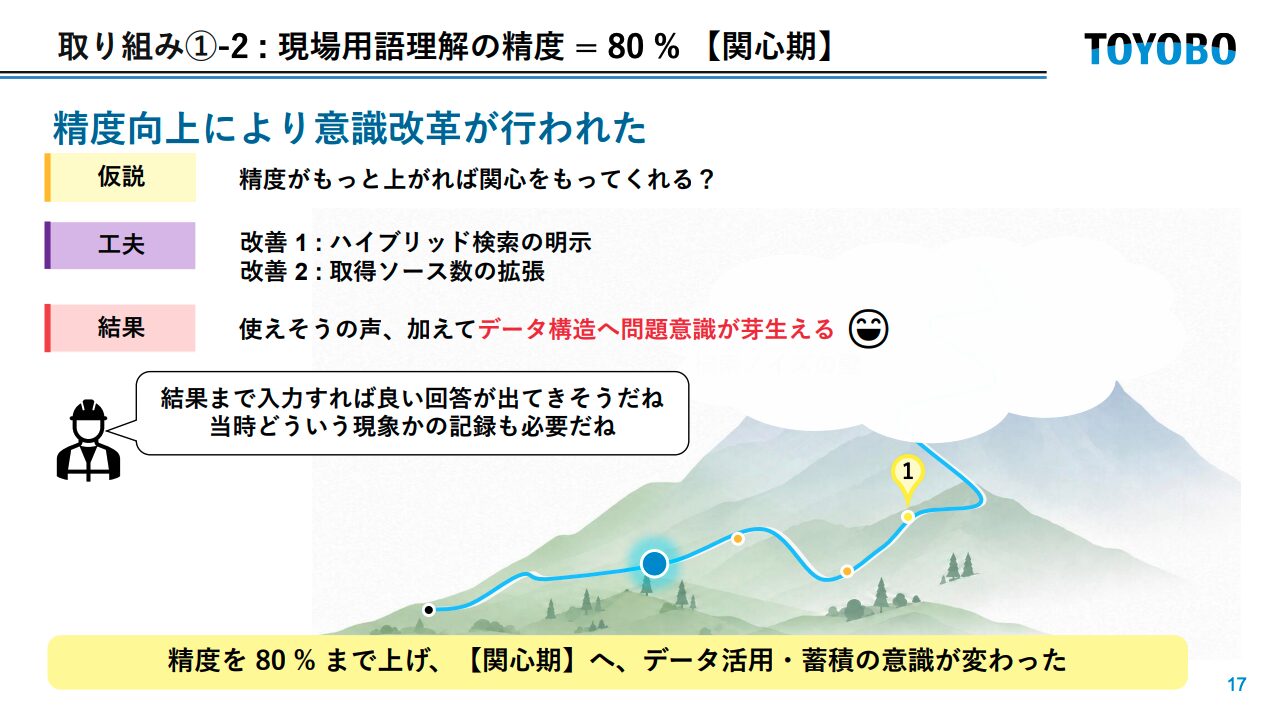
ここで強調されていたのは、精度改善そのものよりも「使えると思わせること」が現場のデータを残す意識を変えたという変化でした。
「検索するAI」から「知識を育てるAgent」へ
精度80%を達成してもなお、新たな壁が示されました。
- 現場用語の壁:未知の用語が次々と出てくる
- 検索ノイズの壁:文書が増えるほど関係の薄い情報も増える
- 継続改善の壁:改善を回し続ける仕組みがない

そこでセッションでは、設計思想の転換が提示されました。
従来:聞いて・探して・答える(一方向の検索体験)
新方針:現場の言葉を理解し、確認し、蓄積し、改善に戻す
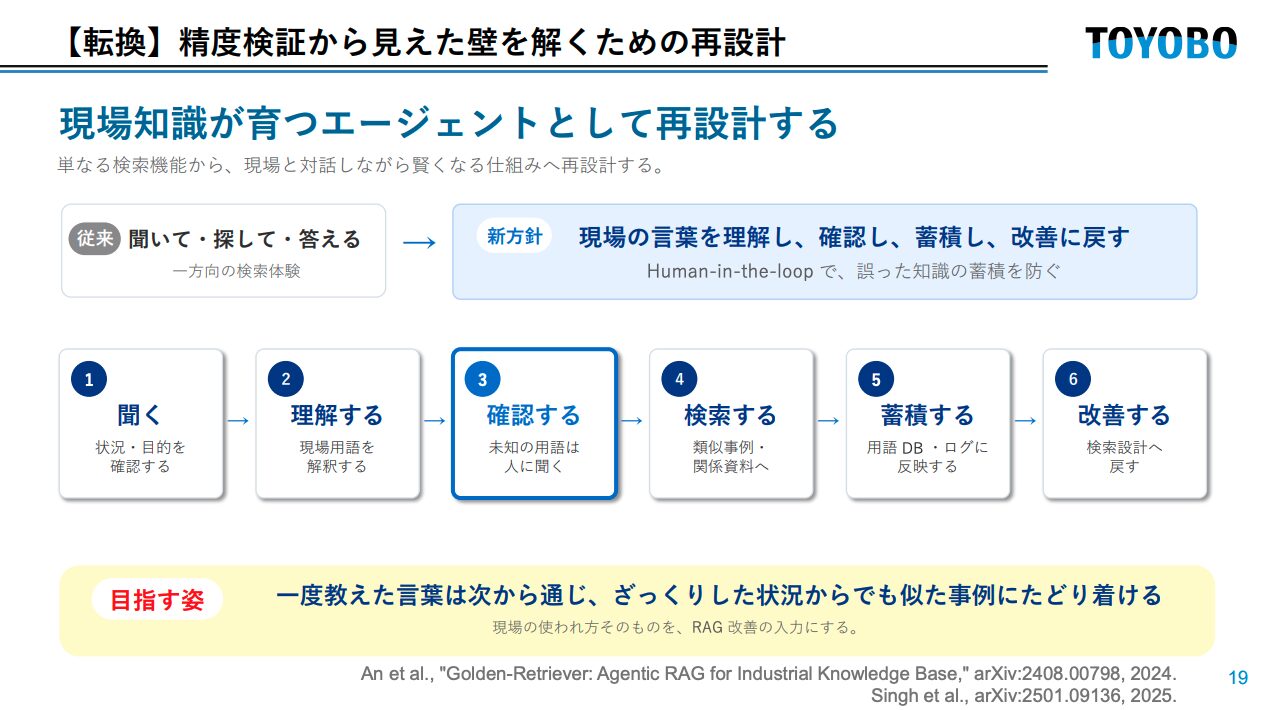
聞く → 理解する → 確認する(未知語は人に聞く) → 検索する → 蓄積する → 改善する
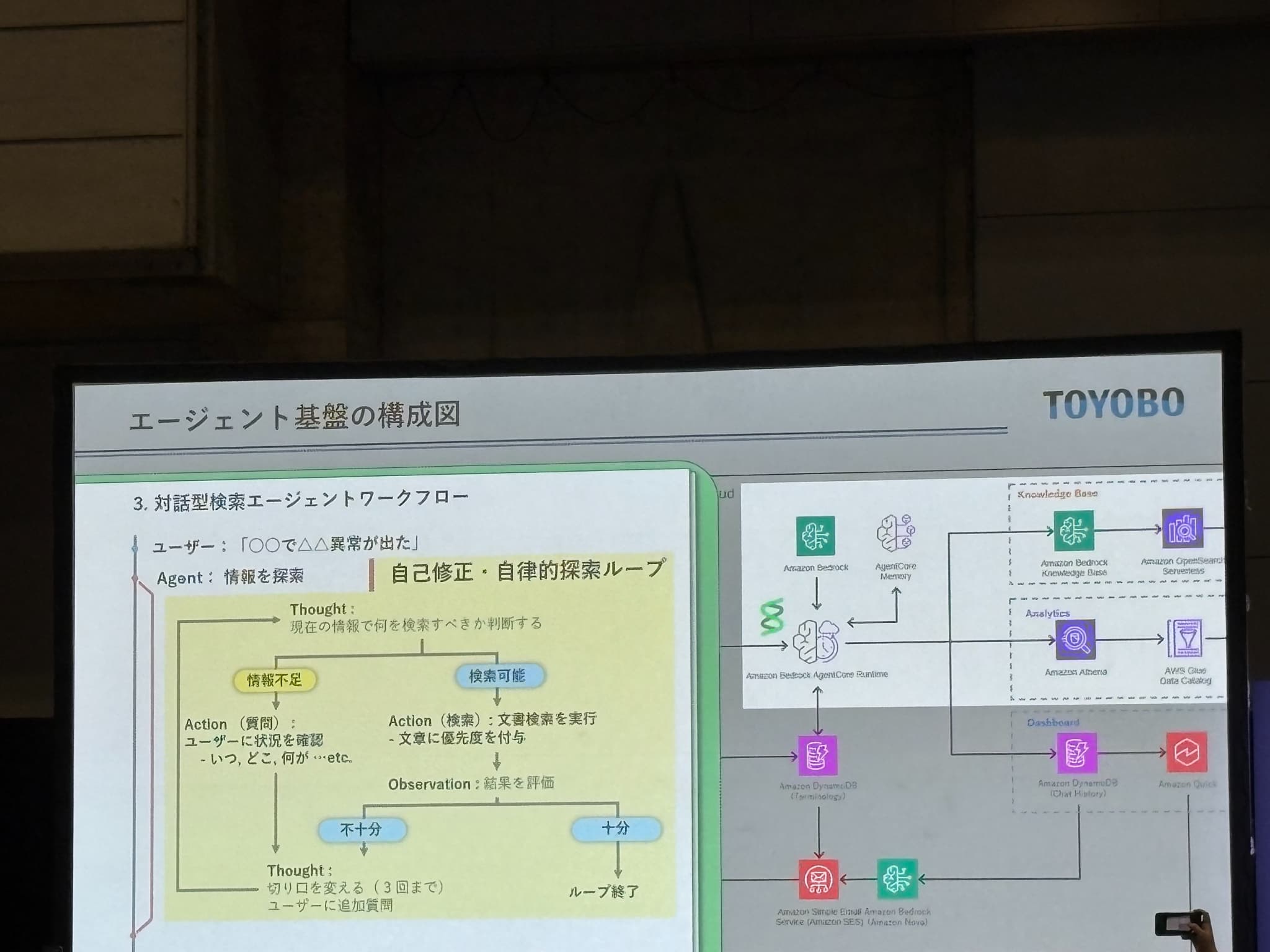
このフローを実現するAWSアーキテクチャとして、Amazon Bedrock AgentCore Runtime を中核に、Knowledge Base(OpenSearch Serverless + S3)、用語DB(DynamoDB)、管理者通知(Amazon SES)、監視(Amazon Nova)を組み合わせた構成が紹介されていました。
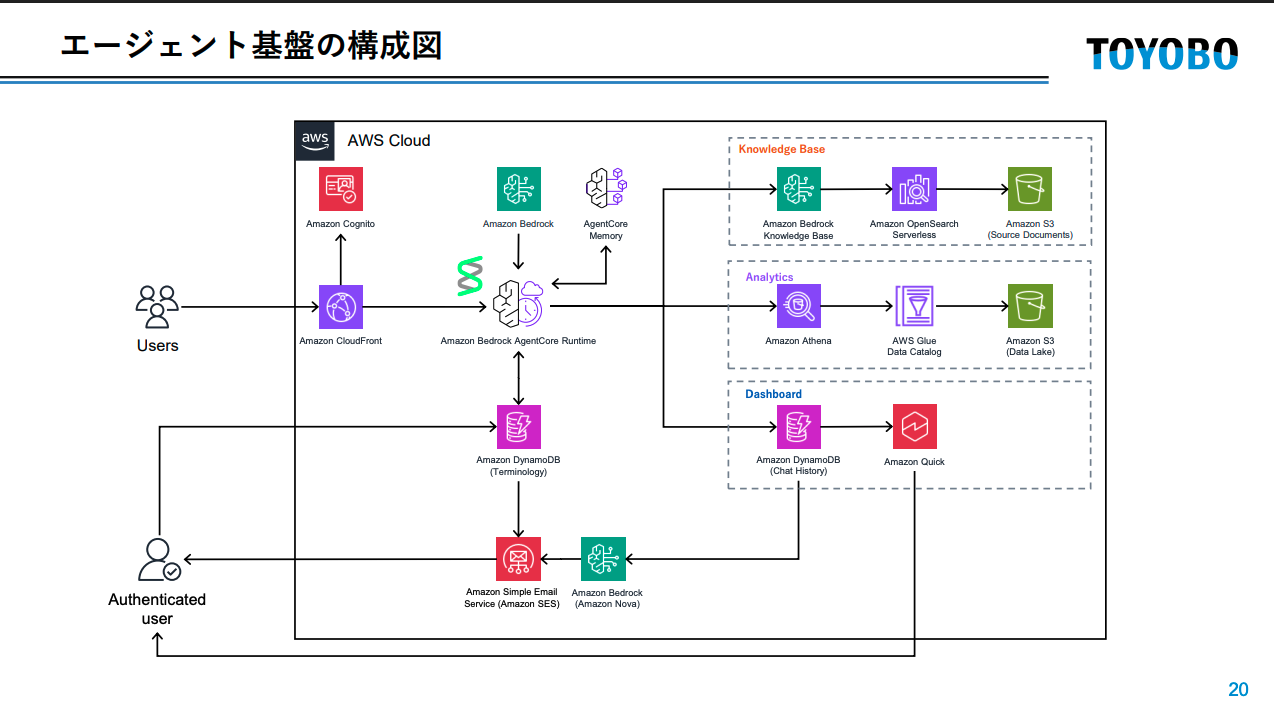
② Human-in-the-loop で用語を蓄積する
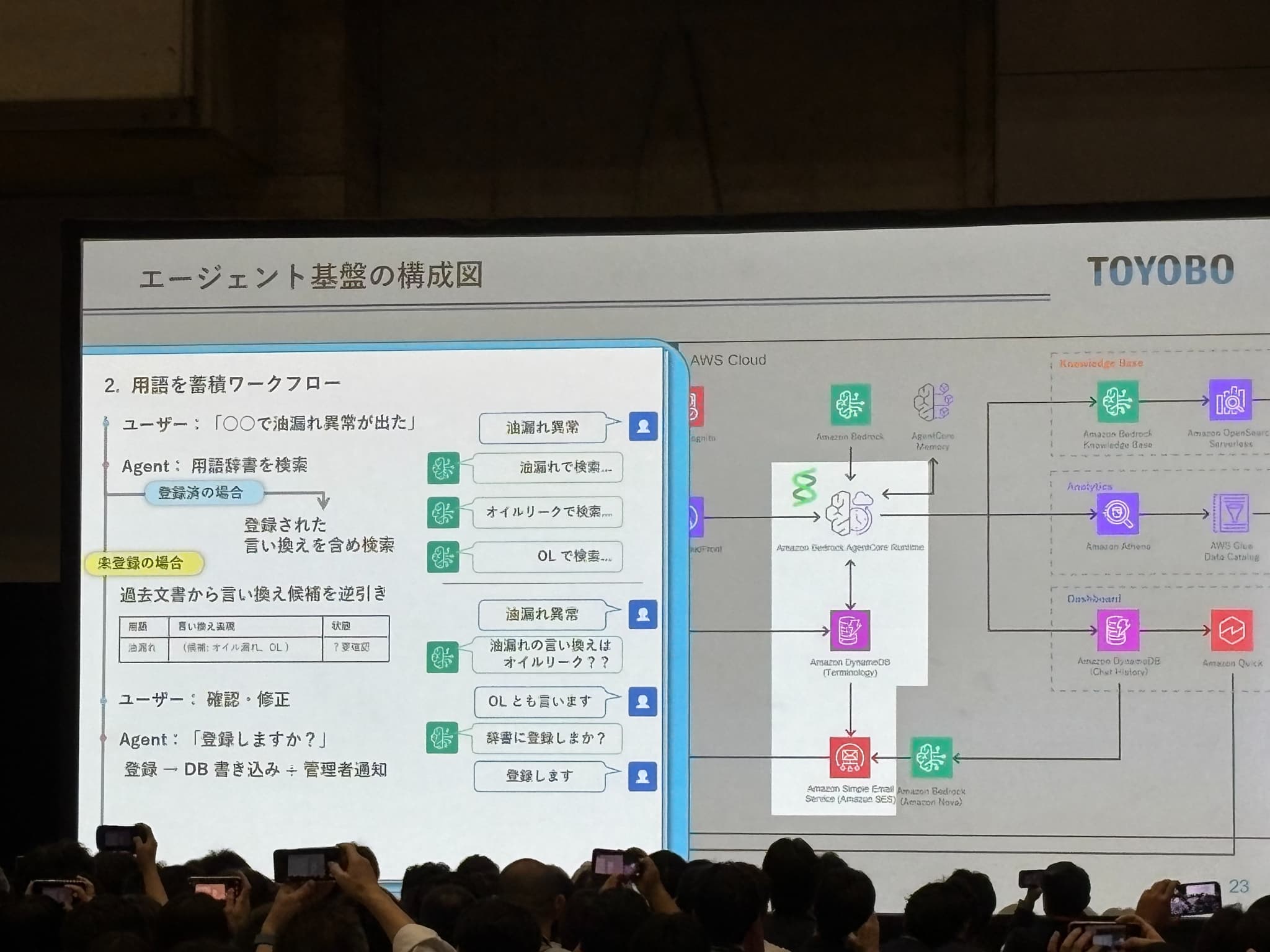
「最初からすべての用語を集め切ることはできない。実際に使ってもらう中で、初めて出てくる言葉がある」という前提のもと、AIが勝手に学ぶのではなく、人と一緒に現場知識を育てるサイクルが設計として紹介されました。
具体的なワークフローとして、以下のような例が示されていました。
- ユーザー「〇〇で油漏れ異常が出た」
- 登録済みの場合:「油漏れ」「オイルリーク」「OL」すべてで並行検索
- 未登録の場合:過去文書から言い換え候補を逆引き → 「油漏れの言い換えはオイルリーク?」とユーザーへ確認 → 「OLとも言います」→ 辞書に登録 → 全Agent・全ユーザーに即時反映
③ 対話型検索エージェント
単語の言い換えが増えるほど検索空間も広がり、ノイズも増えるという問題に対し、AIが「いつ/どこ/何が」を聞き返して検索前に問いを整える設計が紹介されていました。「ざっくりした相談」から「真に求めている情報」へたどり着くためのアプローチです。
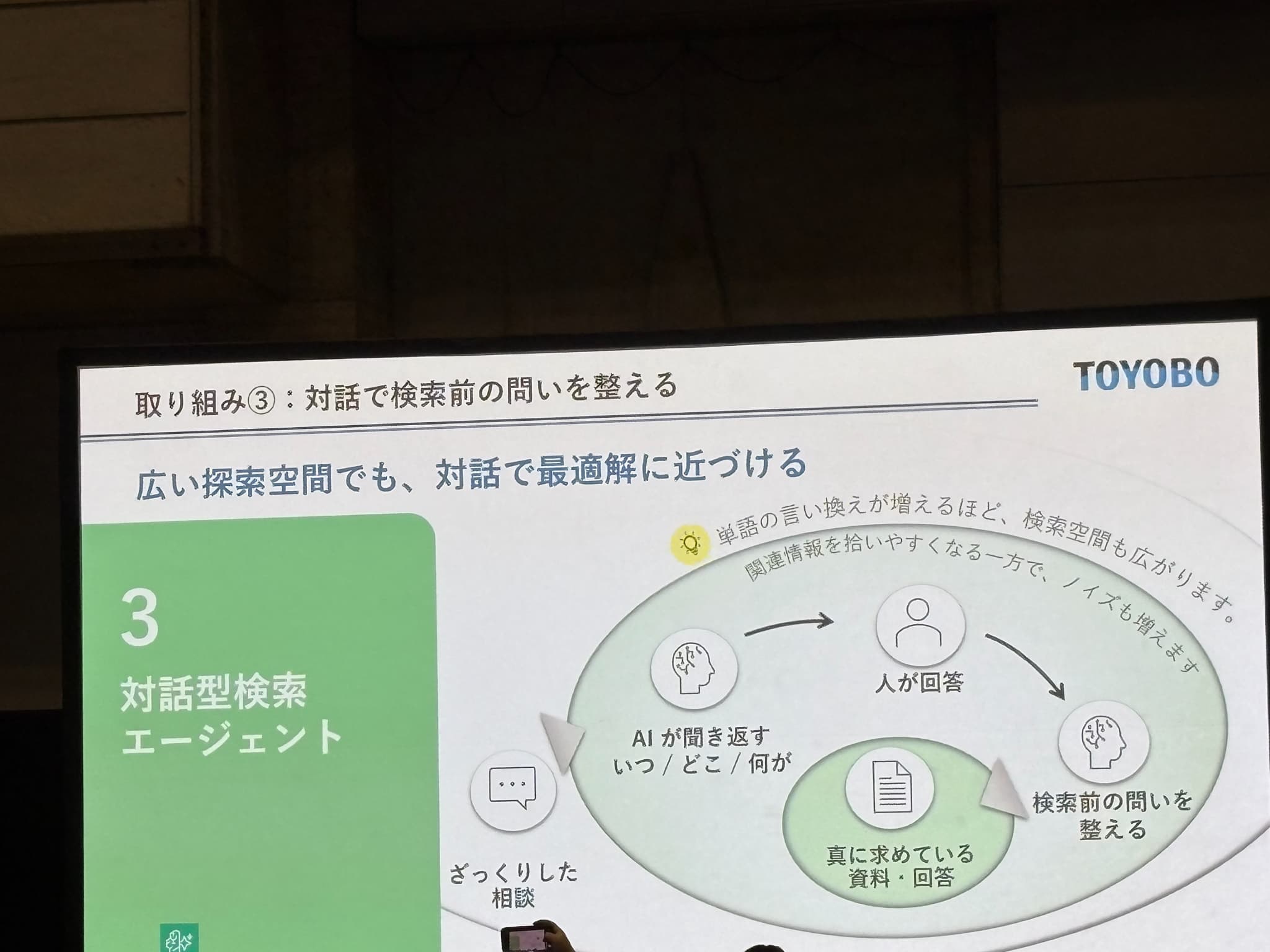
Thought-Action-Observation の自己修正ループで情報不足の場合は角度を変えて最大3回試行し、評価を通過したものだけを提示する仕組みが説明されました。
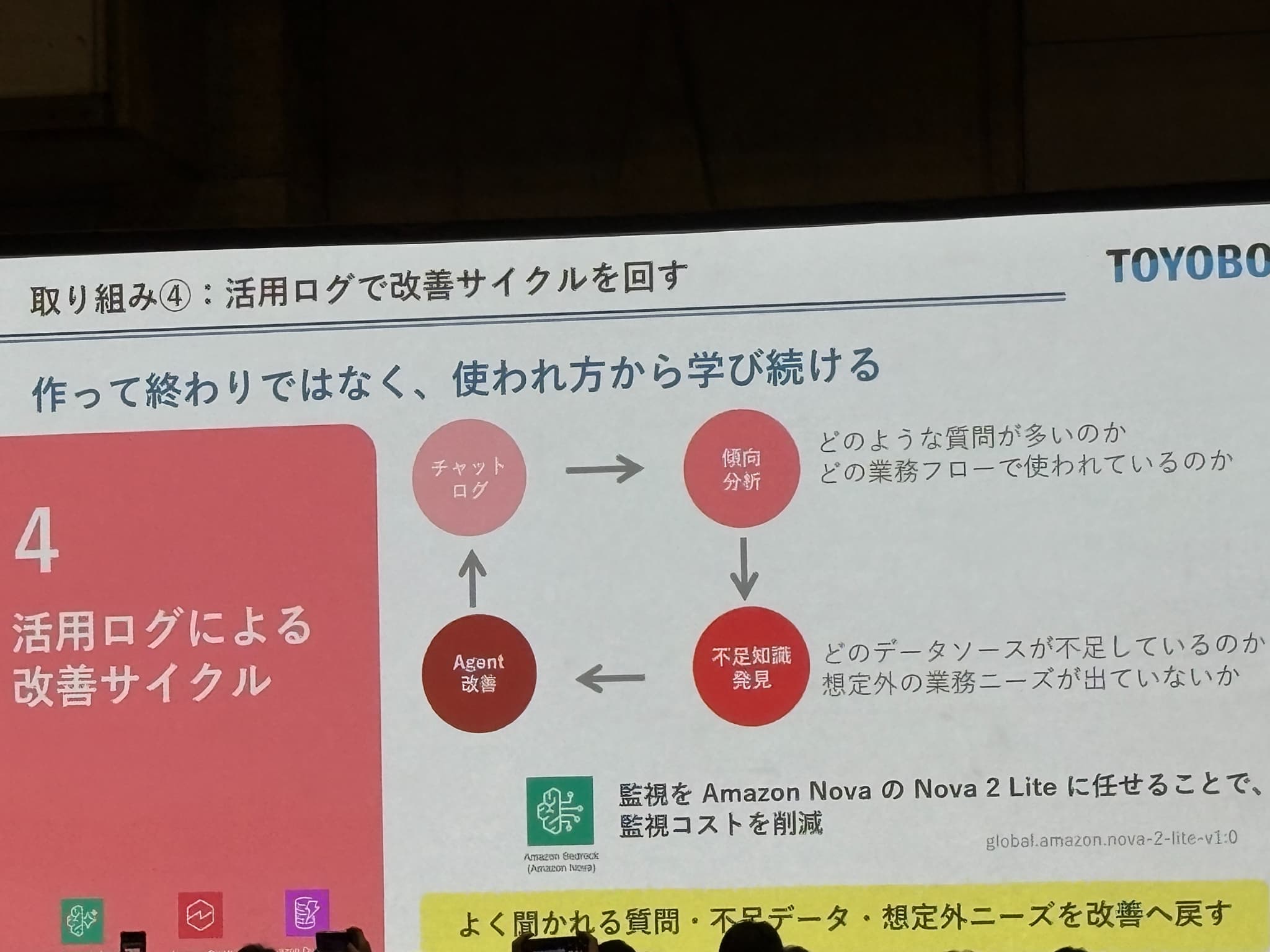
④ 活用ログで改善サイクルを回す
「作って終わりではなく、使われ方から学び続ける」というコンセプトのもと、チャットログ → 傾向分析 → 不足知識発見 → Agent改善のループが紹介されました。監視には Amazon Nova 2 Lite を活用し、監視コストを抑制する工夫も示されていました。
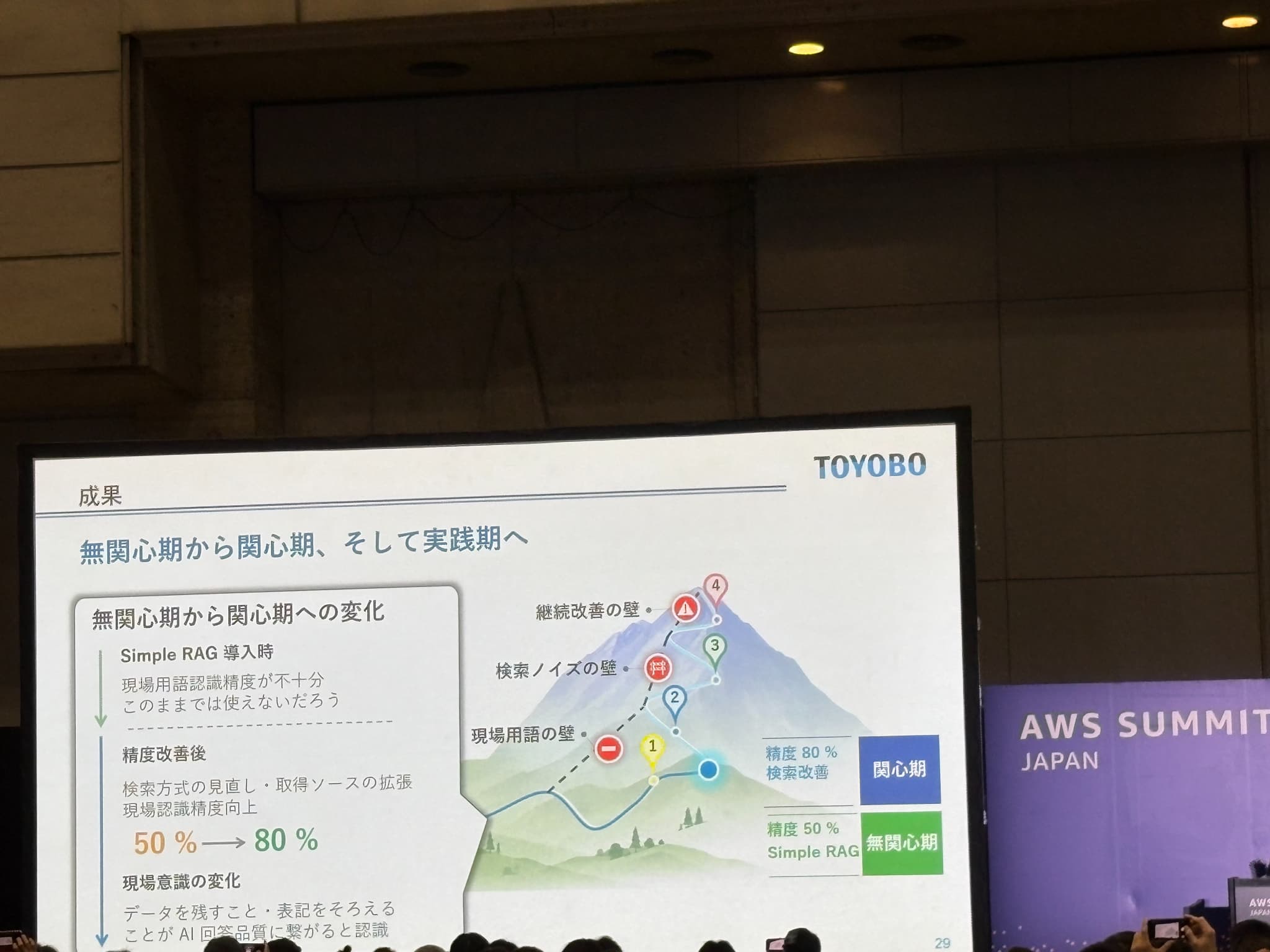
成果
無関心期(精度50% / Simple RAG)→ 関心期(精度80% / 検索改善)→ 実践期(Agentic RAG 現場定着) という変遷が示されていましたが、Agentic RAG 導入から1か月の先行指標として、以下のような結果が得られたとのことでした。
| 指標 | 結果 |
|---|---|
| 関心を持ったユーザー数 | 4 → 120+ |
| 利用率 | 80%+ |
| 継続利用率 | 60%+ |
| 有用回答率 | 70%+ |
| 承認済み用語 | 10件/月 |
また、最後には次のメッセージが示されていました。
「現場が使い、言葉を教え、知識を残し、その結果AIがさらに改善する循環が回り始めた」
「Agentic RAG は、単なる検索ツールではありません。現場の知識を使える形に変え、属人化の解消に向けた第一歩になった」
まとめと所感
「RAGの精度が80%を超えたあたりで、現場の人たちが『これなら当時の現象をちゃんと記録に残そう』と能動的に変わり始めた」という実際のエピソードを聞き、ハッとさせられたセッションでした。
現場で使われるツールとするために、どういった技術要素を用いて実現するかも大事ですが、それ以上に「現場に受け入れられる設計であるか」というところがより重要だなと気づかされました。
また、「独自用語をいかにして検索可能にするか」という課題は自身にとってもかなりタイムリーな話題であり、Amazon Bedrock AgentCoreとHITL(Human-in-the-loop)を用いたAgentic RAGでこんな形で仕組み化できるのかと、非常に学びになりました。
日々、お客様のDX支援に携わらせていただいておりますが、現場の業務ドメイン知識をいかに深く理解し、「現場が『使える』と感じる精度の壁をどう突破するか」まで踏み込んだ設計をしていきたいなと感じました。




