
はじめに
DX開発事業部の田村です。
Google Cloud Next Tokyo 2025のセッションレポートをお届けします。
セッション概要
セッションタイトル: 月間動画再生数約5億回を誇るTVerの、広告配信基盤におけるMemorystore & Bigtable併用戦略と実践的チューニング
登壇者: 髙品 純大氏(株式会社TVer 広告プロダクト本部 プロダクト開発タスク)
TVer は広告型の完全無料でお楽しみいただける民放公式テレビ配信サービスです。2024 年 12 月に月間動画再生数 4.96 億回を記録し、その成長は現在も加速しています。大量の広告リクエストを低レイテンシーで処理する TVer の広告配信基盤では、Memorystore for Redis Cluster と Bigtable を要件に応じて戦略的に併用しています。
本セッションでは、広告配信基盤のような高パフォーマンスが要求されるシステム設計において、NoSQL データベース選定プロセスから設計思想、そしてマネージドサービスの性能を最大限に引き出すための実践的なパフォーマンス チューニングまで、開発者とアーキテクトの皆様に役立つノウハウを余すところなくお伝えします。
TVerとTVer広告

最初に、TVerのサービス概要について説明がありました。
800番組以上というのは圧倒的ですね。これだけのコンテンツ量を支える技術基盤は相当な複雑さがあるはずです。
普段何気なく利用しているサービスですが、改めて数字で見ると本当にすごいスケールですね。
TVer広告の特徴

個人的に興味深かったのは「受容性が高い」という点です。
確かにTVerで動画を見ていても広告に対してそれほど嫌悪感を感じないのは、テレビのCMと同じ感覚で見られるからですね。
広告配信とNoSQL DB
ここからが本題の技術的な話になります。広告配信の仕組みについて詳しく解説されました。
動画広告配信・視聴計測の流れ
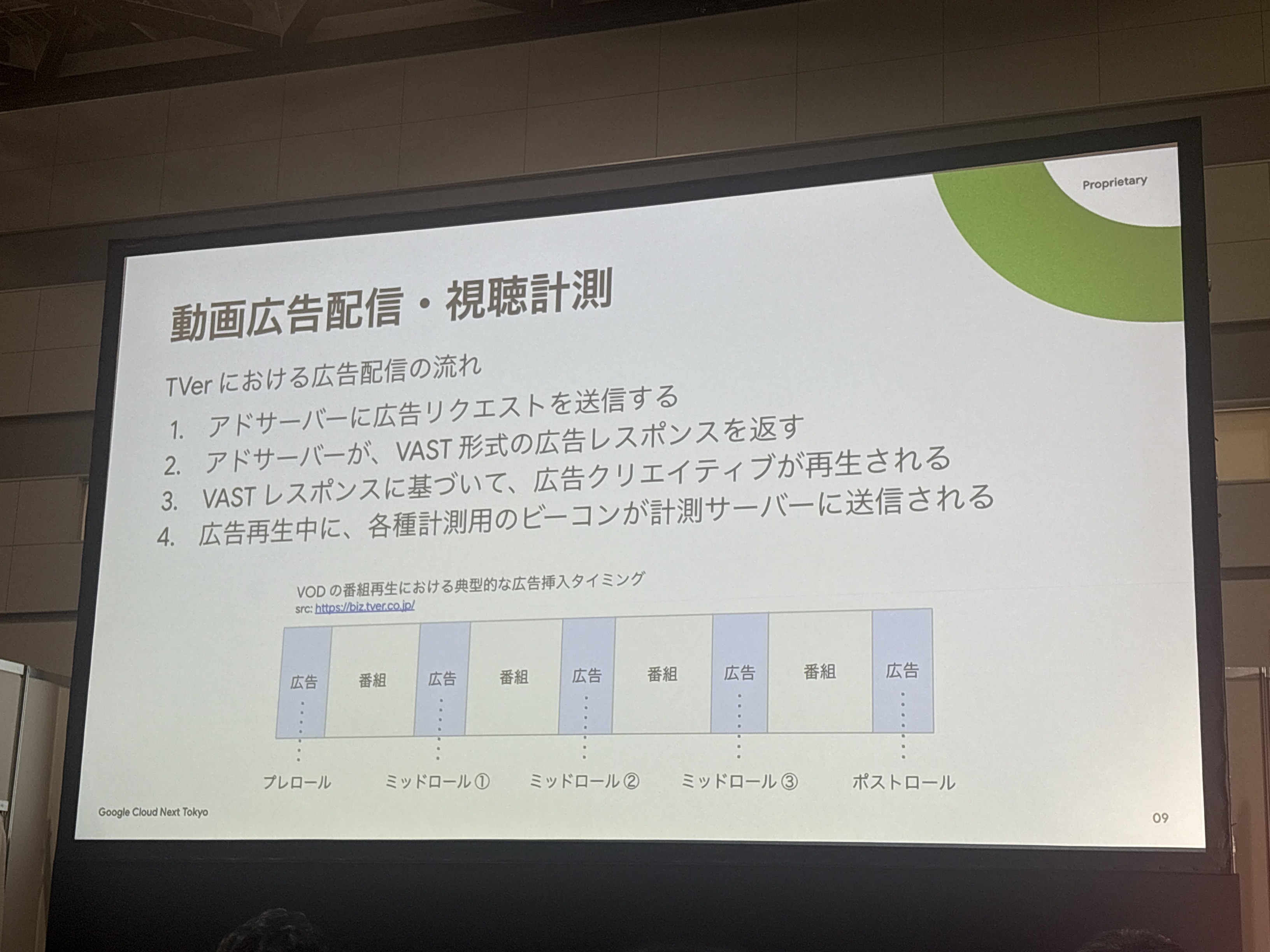
動画広告配信は思っていたより細かく制御されていますね。VAST形式というのは初めて聞きましたが、動画広告業界の標準的な仕様のようです。
アーキテクチャ: TVer Ads Delivery & Measurement System
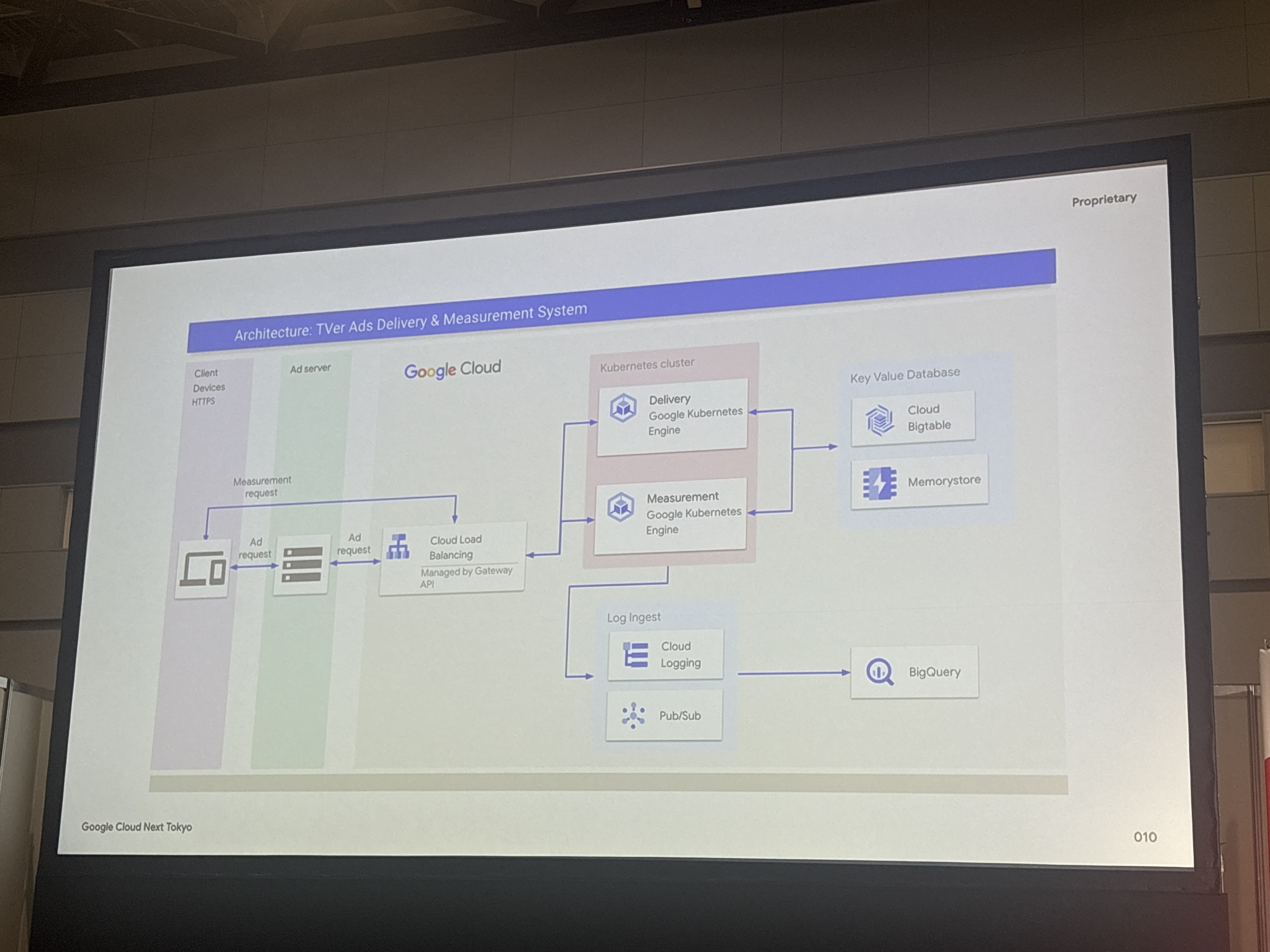
システムは以下のコンポーネントで構成されているようです
- Client (iOS/Android/Web): Ad server、Measurement
- Kubernetes Cluster: Delivery (Google Kubernetes Engine)、Measurement (Google Kubernetes Engine)
- Database: Cloud Bigtable、Memorystore
- Log Ingest: Cloud Logging、Pub/Sub
- BigQuery: データ分析基盤
アーキテクチャ図を見るとかなりシンプルに見えますが、これだけの規模を支えるシステムとしては、各コンポーネントの選択が非常に重要になってきそうです。
Key-Valueデータベースを選んだ理由
ここが今回のセッションの核心部分でした。
なぜKey-Valueデータベースを選択したのかという技術選定の背景について論理的に説明されていました。
広告配信基盤に求められる非機能要件

数百ミリ秒は非常に短いと思いますし、Webアプリケーションでもこれだけ短い時間で処理を完了させるのは結構大変だと思います。
この制約の中で最適な広告を選択するには、従来のRDBでの複雑なクエリ処理では時間が足りません。
確かに広告選択は複雑になりがちということで、レイテンシ要求を満たすためにはこのような割り切りが重要なポイントのようです。
事業の伸長を支える拡張性

事業が成長してもユーザー体験は維持しなければならず「レイテンシの要求は緩まない」というのが、当然な部分ですが難しい要求です。
MRC & Bigtable併用戦略
ここが一番興味深い部分でした。
単一のデータベースではなく、それぞれの特性を活かして使い分けているという点が印象的です。
Key-Valueデータベース

以下の特徴を持つデータベースを比較検討されたそうです
- Memorystore for Memcached
- Memorystore for Redis
- Memorystore for Redis Cluster (MRC)
- Bigtable
MRCでゼロダウンタイムでのスケールアップは魅力的ですね。サービスを止めることなく拡張できるのは運用面で大きなメリットだと思います。
Bigtableについては「コンピューティングとストレージの分離」というアーキテクチャのもと、データの耐久性を高めて、レプリケーションによる高可用性を実現できるのも大きなメリットですね。
MRCへのマイグレーションと課題
実際の運用の中で見えてきた課題と、それに対する解決策について説明されました。これは非常に実践的で参考になる内容でした。
発生した課題の詳細
- 配信サーバーと計測サーバーがアクセスするクラスターが異なると、Bigtableのキーが見つからない場合がある
- 原因はBigtableのレプリケーションレイテンシー(数秒から数十秒)
- セッション書き込み後、読み取りまでのラグが数秒以下だと、アクセス先クラスターによってはキーが見つからない

上図のように、配信サーバーがCluster 1に書き込んだセッションが、計測サーバーがCluster 2やCluster 3にアクセスした際に「rowkey not found」となってしまう問題が発生していました。
書き込みと読み取りの間のラグが数十ミリ秒であるにも関わらず、Bigtableのレプリケーションレイテンシが数秒から数十秒かかるためとのことです。
一貫性モデルによる解決策の検討
- 単一クラスタールーティング: リードアフターライトコンシステンシーで要件を満たせるが、障害時の可用性が低下
- マルチクラスタールーティング: 高可用性を実現するが、イベンチュアルコンシステンシーで書き込み直後の読み取りが保証されない

Bigtableでは一貫性と可用性のトレードオフが発生してしまうため、「書き込み後、数十ミリ秒後に読み取り可能である」要件を持つデータをMRCへマイグレーションすることで課題を解決したようです。
MRCを選択した理由
- 数十ミリ秒という非常に短時間で収束する整合性を提供
- ゾーン障害への耐性を備えている
- 可用性を妥協せずに要件を満たすことができる
実際のプロトタイプで発見された課題とその解決プロセスが非常にリアルで参考になります。
理論上の検討だけでなく、実際に動かしてみて初めて分かる問題があるということですね。
最終的なデータストア選定結果
課題解決を踏まえた最終的なデータストア選定は以下になったようです。

この最終選定では、各データの特性(データサイズ、更新頻度、レイテンシ要求、アクセスパターン)を詳細に分析した上で、最適なストレージを割り当てているのが分かります。
特に「数十ミリ秒で収束する整合性」というMRCの特性を活かした使い分けが印象的ですね。
Bigtable実践的チューニング
1. Warm-up(ウォームアップ)

- 負荷試験中にノード数を固定する
- 負荷試験と同じアクセスパターンで事前に10分以上負荷をかける
Bigtableは約10分程度かけてデータを最適化し、タブレット(テーブルの連続した行範囲)を分割してノードに再配置します。
この最適化プロセス完了前や実施中は特定ノードにアクセスが集中し、レイテンシが遅くなります。
2. gRPC Connection Pool Size調整

- Go、C++、Java用Bigtableクライアントは初期化時にコネクションプールサイズを調整可能
- デフォルト値は4、各コネクションは100個のストリームを持つ
「Warm-up」という概念は非常に重要ですね。分散データベースの特性を理解した上で、本番環境を模した状態で負荷試験を実施する必要があるということです。
コネクションプールサイズの調整で劇的な性能改善
負荷試験では、コネクションプールサイズの問題に直面し、これを解決することで劇的な性能改善を実現していました。
発生した問題
- APIリクエストのクライアントサイド指標のレイテンシが異常に遅くなった
- 同時接続数に対してコネクションプールが不足し、リクエストがキューにバッファリングされて待たされる状態
- アプリケーションのメモリ使用量が増大し、GKEのPodがOOM Killerで強制終了されることもあった
改善結果(具体的な数値)
| 項目 | 調整前 | 調整後 | 改善倍率 |
|---|---|---|---|
| 95パーセンタイルレイテンシ | 49秒 | 112ミリ秒→7ミリ秒 | 7,000倍高速化 |
| メモリ使用量 | 37GB | 523MB | 98.6%削減 |
個人的に刺さったポイント
1. プロトタイプで発見された重大な課題
「配信サーバーがBigtableに書き込んだデータが計測サーバーから見えない」という問題は、理論的な検討だけでは見つからなかった課題です。
実際に動かしてみて初めて分かるレプリケーションレイテンシーの問題を包み隠さず共有していただいたのが印象的でした。
2. 要件ベースの技術選択の重要性
「数百ミリ秒のレイテンシ要求」「書き込み後数十ミリ秒で読み取り可能」といった具体的で厳しい要件から逆算した技術選択プロセスは、非常に参考になりました。
特にBigtableとMRCの使い分けで「一貫性と可用性のトレードオフ」に直面し、要件に応じて最適な選択をしたという点では、机上の空論ではなく実際のビジネス要件に基づいた現実的な判断が随所に見られました。
まとめ
今回のセッションは、月間5億回という圧倒的なスケールを支えるTVer広告配信基盤の技術的な深さと、現実的な開発プロセスの両方を学べる非常に価値の高い内容でした。
Bigtableでの一貫性の問題やコネクションプールの設定など、実際の開発現場で起こりうる問題とその解決プロセスを学べたのは非常に貴重でした。
今後、大規模システムの設計に関わる際は、今回学んだ要件ベースの技術選択と継続的な最適化プロセスを活用していきたいと思います。




