
はじめに
先日開催されたGoogle Cloud Next Tokyo 2025にて、DMM社による「BigQuery 継続的クエリとVertex AIを利用したリアルタイムレコメンドシステムの構築」という興味深いセッションを聴講しました。この発表では、BigQueryの新しい機能である継続的クエリと、Vertex AIを組み合わせることで、いかにしてリアルタイムのレコメンドシステムを効率的に構築したかについて、DMMの具体的な事例を通して深く学ぶことができました。
セッションの概要
このセッションは、BigQueryの継続的クエリとVertex AIを最大限に活用し、いかにしてリアルタイムのレコメンドシステムを構築するかに焦点を当てたものでした。特に、ユーザーの行動に即座に反応した、よりパーソナライズされたレコメンドの実現を目指している点が強調されていました。
セッションの内容
発表の内容を一部紹介します。
1. 課題と背景
DMMではDMM TVやDMMブックスなどの複数サービスでレコメンドシステムが利用されていて、トップページや作品詳細ページ、メールマガジンなどで活用されています。従来のレコメンドシステムにはいくつかの課題がありました。
- データ更新は1日1回バッチ処理で行われており、ユーザーの行動がレコメンドに反映されるまでに1日かかっていました。
- レコメンドは過去の興味関心に基づいていたため、サイト滞在中の行動や、現在の興味関心とのズレが大きいという問題がありました。
- 新規ユーザーへのレコメンドが困難でした。
これらの課題を解決し、リアルタイムでのレコメンドを実現するために、「u2i(user to item)」での検討が進められました。主な検討課題として、以下の5点が挙げられていました。
- サイト滞在中のレコメンド反映
- 現在の興味関心とのズレの最小化
- 新規ユーザーへのレコメンド
- MLエンジニアとMLOpsエンジニアの責任分界点
- 素早いプロダクトローンチ
これらの課題に対し、サイト内ユーザーの行動をリアルタイムに連携し、Google Analytics 4からBigQueryへの連携を進めること、そしてMLエンジニアとMLOpsエンジニアが扱うコンポーネントを明確にし、安全かつ迅速な開発を行うことが方針とされました。
2. アーキテクチャ
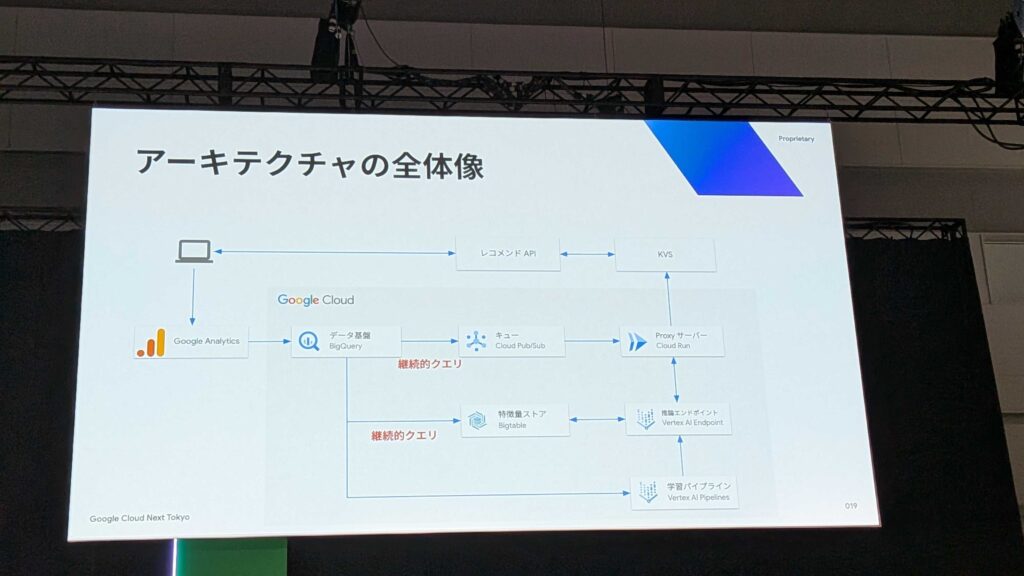
システム全体のアーキテクチャはGoogle Cloudを基盤として構築されています。
BigQueryの継続的クエリは、BigQuery上でSQLを継続的に実行し、リアルタイムなデータ変換を実現する画期的な機能です。BigQueryがストリーム処理エンジンとして機能し、BigQueryに入ってくるデータをほぼ同時に抽出、変換、外部サービスにエクスポートできる点が革新的です。
継続的クエリを採用した理由として以下の2つが挙げられていました。
- GA4連携によるリアルタイムデータ基盤の存在:GA4からBigQueryへのストリーミングエクスポート機能により、イベントが数秒〜1分程度でBigQueryに連携されます。
- SQLでストリーミング処理を実装可能:MLエンジニアが使い慣れたSQLだけで完結できるため、複雑になりがちなストリーミング処理フレームワークの学習コストが不要となり、開発のアジリティが向上します。MLエンジニア一人で高速にストリーミングパイプラインを実装・改善でき、MLOpsエンジニアとのコミュニケーションコストも削減されたとのことです。
具体的なアーキテクチャ詳細としては、以下の流れでデータが処理されます。
- ユーザーの行動ログはGoogle AnalyticsからBigQueryへリアルタイム連携されます(ログの遅延は数秒程度)。
- BigQueryの継続的クエリによって特徴量が生成され、Bigtableにリアルタイム連携されます。
- 継続的クエリは、ユーザー行動ログの発生をトリガーにPub/Subトピックにメッセージを発行します。
- Proxyサーバー(Cloud Run)がメッセージをサブスクライブし、推論エンドポイント(Vertex AI Endpoint)を呼び出します。
- 推論エンドポイントはBigtableに保存された特徴量を用いて推論を行い、結果を返却します。
- Proxyサーバーは推論結果をKVSに書き込みます。
- 別途、Vertex AI Pipelinesによる学習パイプラインが日次で実行され、Two-Towerモデルの学習、Model Registryへの登録、Vertex AI Endpointへのデプロイが行われます。
3. 得られた知見
システム構築を通じて得られた知見として、以下の点が共有されました。
- うまくいったこと:ML/MLOpsエンジニアの分業
- 責任分界点を明確にし、役割ごとの専門性にフォーカスすることで、チームのパフォーマンスを最大化できました。
- MLOpsエンジニアはシステムの安定稼働と開発の効率化、再利用可能な共通基盤の構築に注力しました(アーキテクチャ設計、共通基盤開発、データ品質監視、SLO監視など)。
- MLエンジニアはビジネス価値の創出、モデルの改善サイクルに注力しました(モデルの改善・実験、オフライン評価、学習・特徴量生成パイプラインの実装など)。特にBigQueryの継続的クエリを利用することで、MLエンジニアだけで特徴量生成パイプラインの実装を完結できた点が重要だと強調されていました。
- うまくいったこと:Bigtableのテーブル設計
- オンラインFeature StoreとしてBigtableを初めて採用し、Google Cloud公式ドキュメントのベストプラクティスをMLOpsチームメンバーで徹底的に議論しました。これにより、推論APIからの特徴量取得を低レイテンシで安定稼働させることができたとのことです。
- うまくいったこと:既存資産の活用
- ユーザー行動追跡の基盤や、KVSに格納されたレコメンド結果を返却するAPI基盤、Vertex AI Pipelinesによる継続的なモデル学習基盤など、既存のシステムを最大限活用しました
- 新しく実装する必要があったレコメンドを更新するデータストリーム処理基盤も、継続的クエリの採用により、シンプルかつスピーディに実装できたと述べられていました。
- 苦労したこと:継続的クエリのジョブ管理
- GA4のログテーブルは日次でシャーディングされており、継続的クエリの制約上、テーブルのワイルドカード指定ができません。そのため、日次で継続的クエリが参照するテーブルを切り替える必要がありました。
- これに対し、内製のジョブ管理システムを構築し、新しい日次のテーブルの存在確認を行うポーリング処理と、古い継続的クエリを停止して新しいクエリを開始する仕組みを実装したとのことです。
まとめ
このセッションで最も印象的だったのは、BigQueryの継続的クエリを活用することで、リアルタイムレコメンドの実装がこれまで以上に身近なものになった点です。MLエンジニアが日常的に使用するSQLのみでストリーミング処理まで対応できるため、開発スピードの向上とチーム間の連携効率の両立が実現可能であることが、非常に実践的で参考になりました。
また、MLエンジニアとMLOpsエンジニアの役割分担を明確にし、それぞれが専門領域に集中することで、チーム全体のパフォーマンスを最大化できるという点も強く印象に残りました。
一方で、GA4のログテーブルにおける日次シャーディングという具体的な課題に対し、内製のジョブ管理システムで対応していた点からは、現場での工夫や試行錯誤が感じられ、現実的なシステム構築の視点からも非常に参考になりました。新しい技術を導入する際には、その特性と既存システムとの兼ね合いによって生じる課題に、どのように実践的に対処するかが重要であると再認識させられました。




