
前回のあらすじ
【連載第8回】システムが自分で治す。AWSで実現する「自己修復アーキテクチャ」の作り方
前回、私たちはITILの「規律」とSREの「自動化」を融合させ、障害を検知したシステムが自ら復旧作業を行う「自己修復アーキテクチャ」という、クラウド都市における究極の防災システムを手に入れました。深夜に鳴り響くアラートに叩き起こされ、冷や汗をかきながらコマンドを実行する…そんな悪夢のような日々からエンジニアを解放し、より創造的な仕事に集中できる未来への扉を開いたのです。
さて、このクラウド都市での大きな一歩を、現実世界の言葉に翻訳してみましょう。 この自己修復システムは、「インシデントの平均修復時間(MTTR)を30分から5分に短縮した(例)」という、技術的には輝かしい成果を生み出します。しかし、あなたが胸を張ってこの成果を経営会議で報告した時、こんな言葉が返ってきた経験はありませんか?
「素晴らしい。…で、その25分の短縮は、我が社の売上にとって、一体いくらの価値があるんだね?」
その瞬間、技術の現場と経営の間に存在する、深くて冷たい溝に気づき、言葉に詰まってしまった…。
つまり、私たちの血の滲むような努力によって達成した技術的成果も、ビジネスの言葉に翻訳されない限り、その価値を正しく伝えることは極めて困難なのです。
この「言葉の壁」を打ち破り、エンジニアの貢献を誰もが理解できる「ビジネス価値」へと変換する、いわば“魔法の翻訳機”こそが、今回お話しするSLO(サービスレベル目標)なのです。
この記事でわかること
- なぜ従来の「稼働率99.9%」といった技術指標(SLA)だけでは、ビジネスの成功を測れないのか。
- SLO(サービスレベル目標)が、ユーザーの満足度と事業の売上を結びつける「共通言語」になる理由。
- エンジニア、ビジネスサイド、経営層が同じ目標を目指すための「統合ダッシュボード」という未来像(To-Beモデル)。
- あなたの頑張りを「コスト」から「投資」へと変える、新しいKPIマネジメントの考え方。
なぜ「稼働率99.9%」はユーザーを幸せにしないのか?

AmazonのCTOであるWerner Vogels氏が言うように、「あらゆるものは常に故障する (Everything fails, all the time)」のです。この現実を前にして、私たちITの世界では長年、システムの品質を「SLA(サービスレベルアグリーメント)」、特に「稼働率」という指標で測ってきました。
しかし、この数字には大きな罠が潜んでいます。最新のAWS公式ブログでも解説されている通り、SLAはあくまで顧客と結ぶ厳格な「契約」であり、未達の場合の補償を定めるものです。それ自体が、ユーザーの満足度やビジネスの成功を約束するものではありません。
【出典】AWS クラウドオペレーションと移行ブログ:効果的な SLO でアプリケーションの信頼性を向上
考えてみてください。ECサイトが稼働率99.9%を達成していても、サイトの表示は異常に遅く、肝心の決済ボタンをクリックしても反応がない…。この状態は、ユーザーにとって「サービスが動いている」と言えるでしょうか?答えは、もちろん「ノー」です。
従来のSLAは、多くの場合、都市に電気が通っているか(サーバーが起動しているか)だけを問うようなものでした。しかし、市民(ユーザー)が本当に求めているのは、「蛇口をひねれば、いつでも綺麗な水が快適に出てくる」という体験そのものです。
技術的な稼働率と、ユーザーが実際に感じるサービス品質(ユーザー体験)との間には、大きな乖離があるのです。この乖離こそが、エンジニアの努力がビジネス価値として認識されない根本原因なのです。
SLO:ユーザーの「幸福度」を測る新しいモノサシ
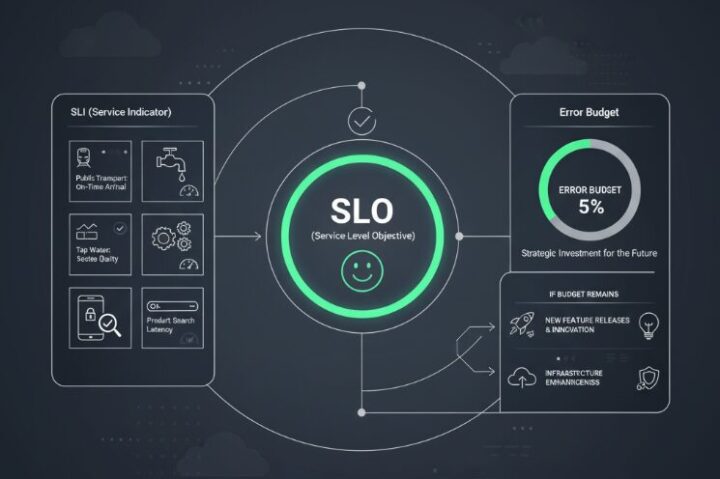
そこで登場するのが、SLO(サービスレベル目標)です。難しく考える必要はありません。これは、技術的な指標をユーザーの「幸福」という視点に翻訳し、関係者全員で共有するための、いわば三位一体のフレームワークです。
私たちのクラウド都市を例に、以下の3ステップで見ていきましょう。
ステップ①:SLI (指標) – まずは「幸福のモノサシ」を決める
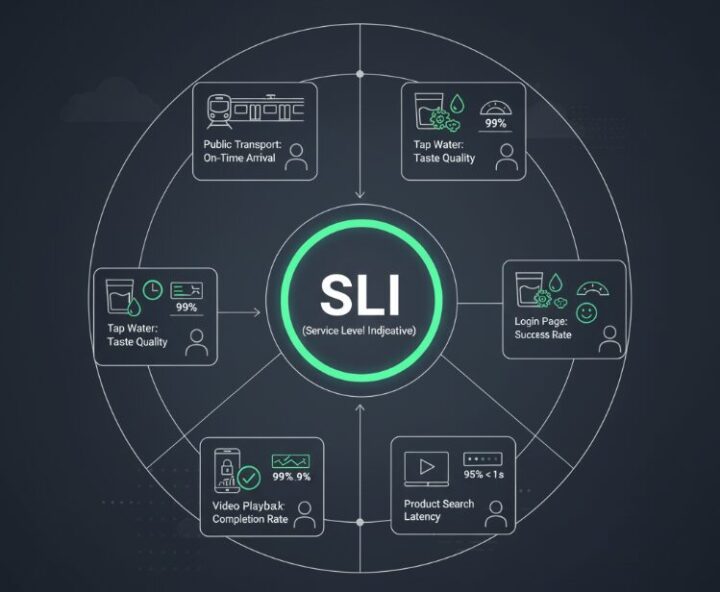
最初に考えるのは、「そもそも、この都市の市民(ユーザー)は何をもって『幸せ』と感じるのか?」という点です。これを測るための具体的な「モノサシ」がSLI (Service Level Indicator) です。
従来の「サーバー稼働率」のような裏側の話ではなく、ユーザーが直接体験する品質に着目します。
- 都市のモノサシの例
- 「公共交通機関が、どれだけ時間通りに来るか?」
- 「水道水は、美味しいと感じるか?」
- Webサービスのモノサシ (SLI) の例
- 可用性SLI:ログインページの表示が成功したリクエストの割合
- レイテンシSLI:商品検索結果が返ってくるまでの時間
- 品質SLI:動画が途中で止まらずに再生完了した割合
ステップ②:SLO (目標) – 次に「幸福度のゴール」を約束する
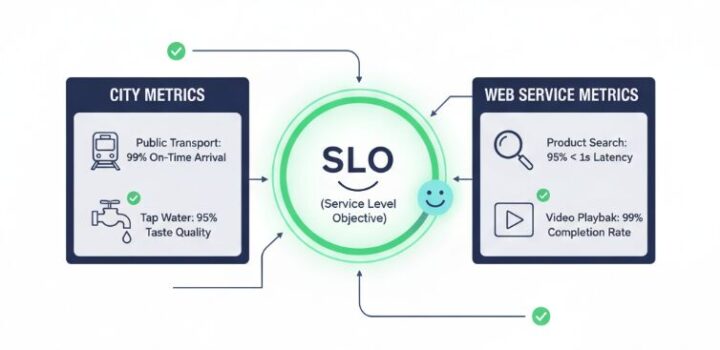
モノサシ(SLI)が決まったら、次はそのモノサシがどれくらいの数値を達成すれば、市民(ユーザー)は十分に幸せだと見なせるかという具体的な“目標値”を定めます。これがSLO (Service Level Objective) です。
- 都市の目標値の例
- 「公共交通機関の99%が、定刻通りに到着する」
- Webサービスの目標値 (SLO) の例
- 「商品検索結果を、95%のリクエストにおいて1秒以内に返す」
これは、私たち開発者がユーザーに対して行う「サービスの品質に関する公約」と言えます。
ステップ③:エラーバジェット (予算) – 最後に「未来への投資枠」を確保する
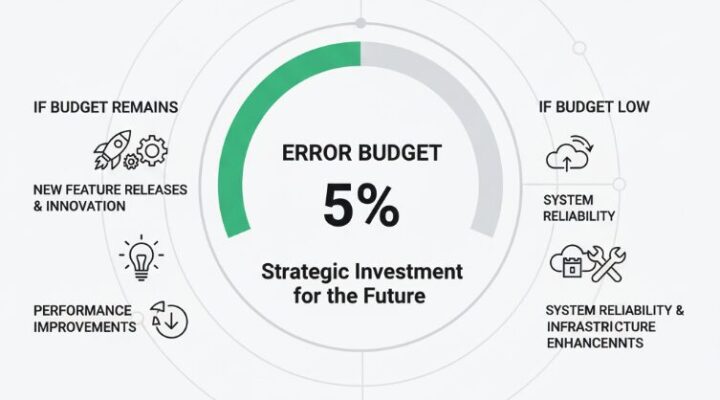
さて、目標を100%にしないのが重要なポイントです。SLOが100%ではない残りの部分、例えば上記の例で言えば「目標を達成できない残りの5%」がエラーバジェットです。
これは決して「許容される失敗」ではありません。むしろ、「ユーザーの信頼を失わない範囲で、未来のために挑戦(新機能リリースやインフラ改善)を行うために与えられた、戦略的な投資予算」なのです。
- 都市での活用の例
- 「定刻通りの運行率を99%に保てている(エラーバジェットが残っている)から、今月は新しい路線のテスト走行を実施しよう」
- Webサービスでの活用の例
- 「エラーバジェットが十分に残っているから、今週は新機能をリリースしよう。もし予算を使い切りそうなら、次の開発ではシステムの信頼性向上に集中しよう」
このように、SLIで現状を測り、SLOで目標を定め、エラーバジェットで改善と挑戦のバランスを取る。この3ステップが、技術とビジネスを繋ぎ、データに基づいた意思決定を可能にするのです。
そして最も重要なのは、これが単なる技術的な作業ではないということです。 先ほどのAWS公式ブログが「SLOの定義は、ビジネスチームと技術チームの双方が協力して行うべきプロセス」だと結論付けているように、SLOの策定とは、技術的な現実とビジネスの目標、そして顧客の期待をすり合わせるための「対話の場」そのものなのです。
技術指標が「売上」に変わる瞬間 (To-Beモデル)

さて、ここからが本題です。この「ユーザーの幸福度」を、どうやって「売上」という経営言語に翻訳するのでしょうか。その鍵は、SLOとビジネスKPIを一枚のダッシュボードで可視化するという、私たちが目指すべき未来の姿(To-Beモデル)にあります。
想像してみてください。あなたの会社の経営会議室のモニターに、こんなダッシュボードが映し出されています。例えば、これは Amazon Managed Grafana や、AWSネイティブの機能として登場した Amazon CloudWatch Application Signals のようなツールで実現できる、部門の壁を越えた「統合市政モニター」です。
【統合市政モニター:xx事業部 2025年9月度】
※記載している数値はイメージのためのサンプル値です。
- 共通言語の確立
- エンジニアは「トップページの表示速度が0.2秒悪化し、エラーバジェットを消費しています」と報告します。ビジネスサイドは、それが「機会損失80万円に繋がりかねない危険なサインだ」と瞬時に理解できます。これにより、言葉の壁は実質的になくなるのです。
- データ駆動の意思決定
- 「エラーバジェットに余裕があるから、来週はA/Bテストを積極的に行おう」「SLOが悪化傾向にあるから、次の開発スプリントはパフォーマンス改善に全リソースを集中させよう」といった、勘や経験ではなく、リアルタイムのデータに基づいた、合理的で迅速な意思決定が可能になります。
- エンジニアの価値の可視化
- インフラチームが実施したデータベースのチューニング結果が、単なる「CPU使用率の低下」ではなく、「決済完了時間の0.5秒短縮」→「コンバージョン率0.1%改善」→「月次売上+150万円」という形で、明確なビジネス貢献として可視化されるのです。
これは、エンジニアがコストセンターという誤解を解き、事業の成長を牽引するプロフィットセンターへと変貌を遂げるための、重要な一歩です。私たちの役割は、もはやサーバーのCPU使用率を下げるといった内向きの改善に留まりません。SLOという共通言語を手に、自らの技術力が「コンバージョン率の改善」や「売上向上」にどう直結するのかを証明し、ビジネスを加速させるグロースエンジン(事業成長の原動力)そのものなのです。
まとめ:「言葉の壁」を壊し、価値を語り始めよう
SLOは、単なる新しい技術指標ではありません。それは、部門間に横たわる「言葉の壁」を打ち壊し、「ユーザーに最高の価値を届ける」という唯一の目的に向かって、組織の全部門が同じデータを見て、同じ言葉で対話するための文化そのものです。
私たちが目指す次世代MSPの姿は、まさにお客様の組織にこの文化を根付かせる「推進役」となることです。
単にAWS環境を監視・運用するだけではなく、お客様のビジネスKPIを深く理解し、それを達成するためのSLI/SLO設計を共に考え、統合ダッシュボードを構築し、データに基づいた改善サイクルを回し続ける戦略的パートナーとなる。これこそが、私たちが描く未来像です。
この記事を読み終えたあなたに、最初の一歩として問いかけたいと思います。
あなたのサービスで、ユーザーが最も「がっかりする瞬間」はどこですか?
まずはその瞬間を一つだけ選び、ビジネスサイドのメンバーと一緒に、それを計測するためのSLIと、目指すべき幸福度の目標値(SLO)を定義することから始めてみませんか。
その小さな一歩が、あなたのチームの頑張りを、正当なビジネス価値として輝かせるための、挑戦の始まりになるはずです。
次回予告
強固な基盤、賢明な財政、未来を予測する防災センター、そして自律的な修復システム。私たちのクラウド都市は、驚異的な回復力と安定性を手に入れました。
しかし、どれだけ頑丈なインフラを築いても、都市開発のルール(開発プロセス)にセキュリティが組み込まれていなければ、新しいビルが建つたびに新たな脆弱性が生まれてしまいます。「開発スピードを上げたい、でもセキュリティも確保したい」…この永遠のジレンマに、多くの組織が頭を悩ませています。
「セキュリティは開発のブレーキである」――この古い常識を、私たちは覆したいと考えています。
次回は、セキュリティを開発のブロッカーではなく、開発者が安心してアクセルを踏み込めるための「ガードレール」として再定義します。ITILの思考をベースに、DevSecOpsの文化をどう組織に根付かせるのか。そして、AWS Security HubのようなサービスをITILの価値連鎖の各段階にどう組み込み、安全とスピードを両立させるのか。その具体的なビジョンを語ります。
【第10回】セキュリティを「ガードレール」に。ITIL思考で実現するDevSecOps文化 にご期待ください。
過去の連載はこちら
これまでのバックナンバーを見逃した方は、こちらからご覧いただけます。
- 【連載第1回】AWSという都市は、なぜ「カオス」と化すのか?
- 【連載第2回】ITILはクラウド運用の「標準OS」。AWS公式が示す、その深い関係性
- 【連載第3回】あなたのMSPは「サポーター」? それとも「戦略的パートナー」? 未来を共創する関係性の見極め方
- 【連載第4回】ITILの心臓部「SVS」をAWSで動かす設計図
- 【連載第5回】なぜ障害対応は「モグラ叩き」で終わるのか? 災害に強い都市を造るITILインシデント管理術
- 【連載第6回】 「クラウド貧乏」を卒業。コストを価値に変えるFinOps文化
- 【連載第7回】 「アラート疲れ」に終止符を。AIOpsで障害を未然に防ぐ
- 【連載第8回】システムが自分で治す。AWSで実現する「自己修復アーキテクチャ」の作り方
クラウド運用に関するお悩みや、これからのパートナーシップのあり方にご興味をお持ちでしたら、どうぞお気軽にお声がけください。あなたのビジネスが直面している課題について、ぜひお聞かせいただけませんか。
