
DX開発事業部 フルスタックセクションの田村です。
Google Cloud Next 2026 よりセッションの要点解説をお届けいたします。
今回は「Data Validation at Scale: Architecting an AI-Native Validation Engine」というSolution Talkを聴講しました。
はじめに
CVS Healthという米国最大規模のPBM(薬剤給付管理)事業を行っている企業による登壇で、同社では8,700万人の医療保険加入者をカバーし、毎日2TBのデータがBigQueryに入っているそうです。
このスケールでデータ品質を担保するにはどうすればいいかという課題とアプローチ方法について説明いただいたセッションでした。
リアクティブからプロアクティブへ
データ品質を担保していくには、まずどの5次元で測るかという観点が重要と説明がありました。

- Completeness(欠損なし)
- Accuracy(ソースとの一致)
- Consistency(スキーマ整合性)
- Timeliness(SLAどおりの鮮度)
- Validity(フォーマット準拠)
CVS Healthでは数十の事前に整理されたデータセットに400〜500の要素があり、これを数千テーブル規模でカバーする必要があります。
対策を講じるまでは「リアクティブ(問題が起きてから対応)」という状態だったため、ダッシュボードに問題が出てから気づくということが少なくなかったようでした。
これが大きな問題になったインシデントについて、ある日に毎日10〜15k件だったレコードが突然80k件になり、誰も気づかないまま消費層まで流れてしまいおかしな数字が出て初めて原因の究明に動き出したという事例が紹介されました。
この規模になると問題が発生してからの原因究明や切り戻しなどを考えると、途方も無い検証と対応が必要となりそうで目を背けたくなりますね。
事前に検証をするなど対策ができていれば被害がもっと少なくなったのかと思います。

これを変えるために設計した新フレームワークが以下の3ステップです。
- Discovery(BigQueryのスキーマを自動スキャン、ドキュメント依存から脱却)
- Scalable Validation(LLMがSQLテストスクリプトを動的生成)
- Integrated Governance(企業ダッシュボード・アラートに統合)
アーキテクチャ:2層構造と2つの技術的難所
バリデーションエンジンの全体像を示したのがこのライフサイクル図です。
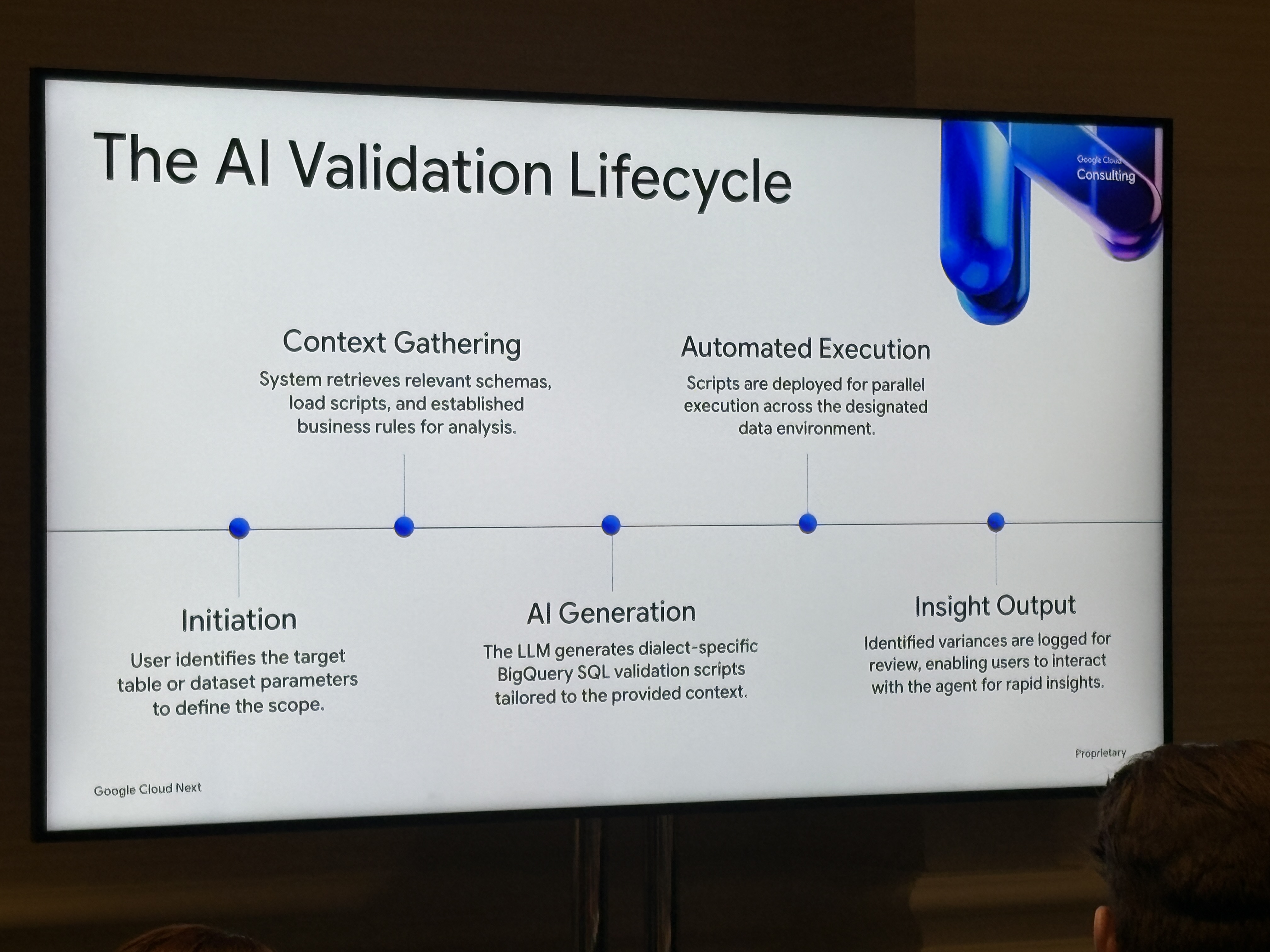
- Initiation(テーブル・データセットの指定)
- Context Gathering(スキーマ・ビジネスルール取得)
- AI Generation(LLMがBigQuery方言のSQLを生成)- Automated Execution(並列実行)
- Insight Output(差分をエージェントに問い合わせ)
「Intelligence LayerとOrchestration Layerの2ブロックに分ける」という設計で合意された様ですが、実際には2つの技術的難所が存在しているとのことでした。
難所1:大規模スキーマ
テーブルによっては2,000カラムあるため、すべてをLLMに渡すとすぐにコンテキスト上限に達してしまいます。
そのため最初はビジネス列・技術列で分割を試みましたが、JSON型やSTRUCT型がトークンを大量消費するため、データ型でグルーピングして15〜50カラムずつチャンクするというアプローチに落ち着き、さらに「count_tokens APIで事前に計測して送信可否を判断するtoken-aware chunking」を開発中とのことです。
難所2:数十億行のテーブル
全件スキャンコスト的にもパフォーマンス的にも非現実的ですが、「パーティション日付ベースのテスト」を導入して、昨日の検証済みのデータは再テストしないという運用フローを入れて新規パーティションのみを対象にすることで、コストと時間を大幅に削減できたということでした。
構築されたアーキテクチャ
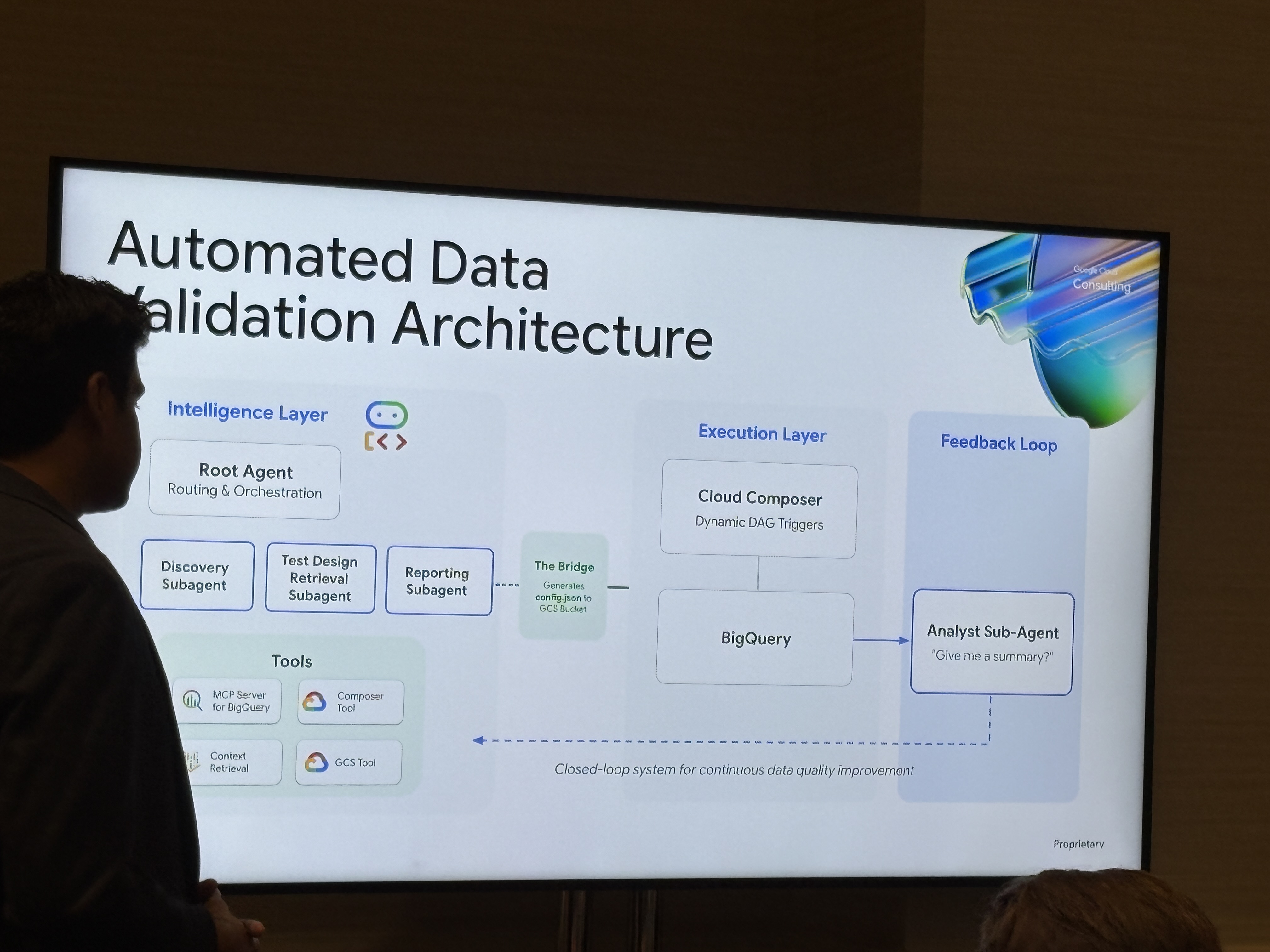
Intelligence Layer(Vertex AI)
Root Agentが3つのサブエージェントを束ね、Discovery Subagent(BigQueryのinformation_schemaからテーブル統計を取得)、Test Design Retrieval Subagent(RAGで過去パターン・SME知識を検索)、Reporting Subagent(結果を構造化)、MCP Server for BigQuery・Composer Tool・GCS Toolをツールとして利用をします。
The Bridge
Intelligence LayerとExecution LayerをつなぐのがThe Bridgeというレイヤーを設けて、エージェントが生成したテスト定義をconfig.jsonとしてGCSバケットに書き込んで、それをManaged Service for Apache Airflow(旧:Cloud Composer)が拾って動的にDAGを生成・実行します。
その後BigQueryで検証クエリが走り、結果はAnalyst Sub-AgentがNL-to-SQLで分析し、「expected 55 counts, but found 5」のように自然言語で報告するフィードバックループが閉じます。
重要なポイントとして強調されていたのが「既存のワークフローを壊すな」という設計方針で、すでに動作しているDAGのパイプライン自体は変更しないようにしてAIはそこに割り込まず、config.jsonを渡すことでオーケストレーションを委譲する。この境界の引き方が現実的なアプローチとのことでした。
デモ:SQLを渡すだけで検証が走る
ライブデモはADK(Agent Development Kit)のUIで行われました。
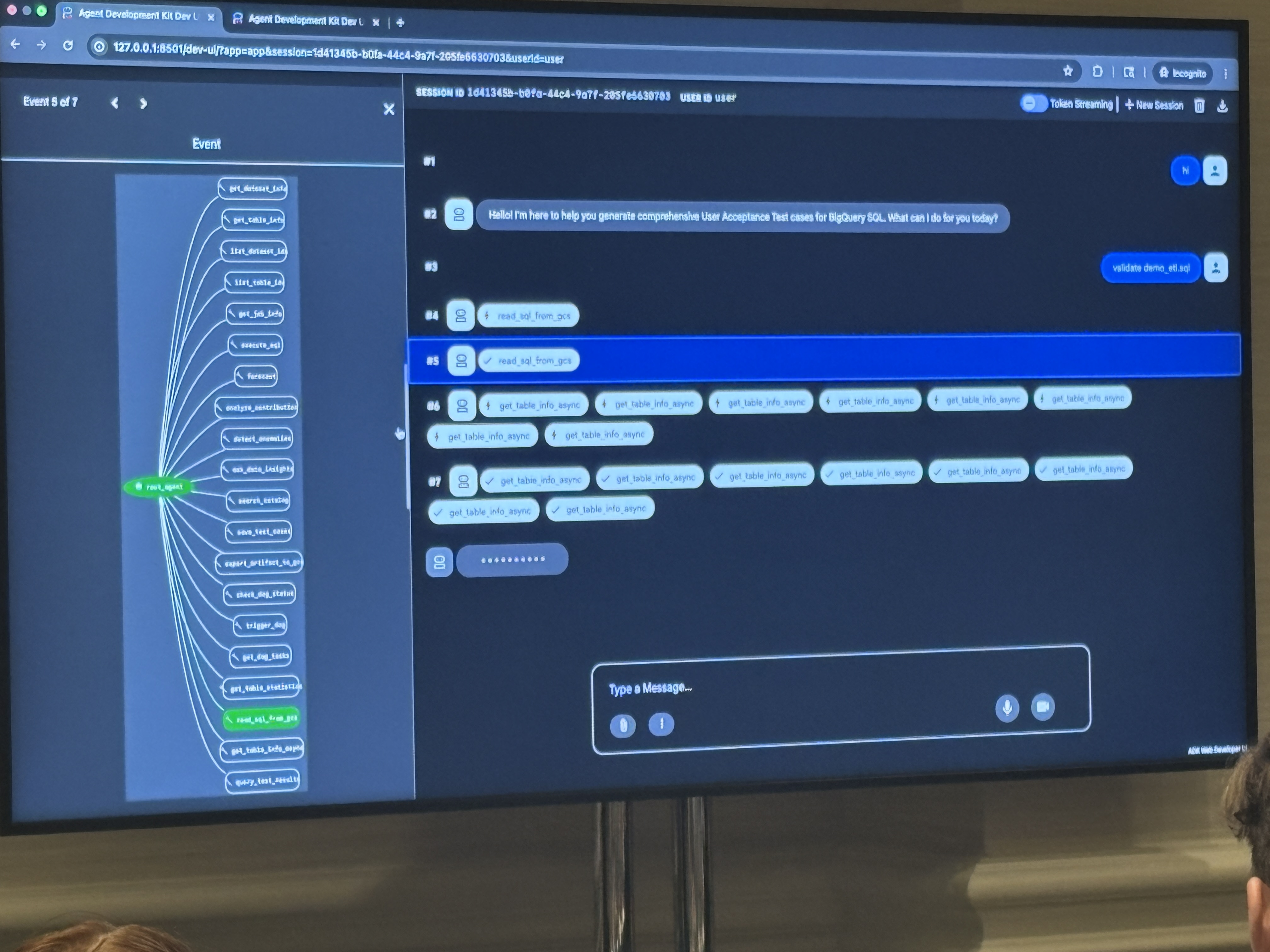
ユーザーが「validate demo_etl.sql」と入力すると、エージェントがGCSからSQLを読み込んで、複数テーブルのtable_info_asyncを並列取得し始めます。
これによりELTスクリプトが参照する複数テーブル(order_items、dim_customer、dim_products等)のスキーマと統計をすべて収集します。
その後、エージェントがテストケース生成のサマリーを出力しました。
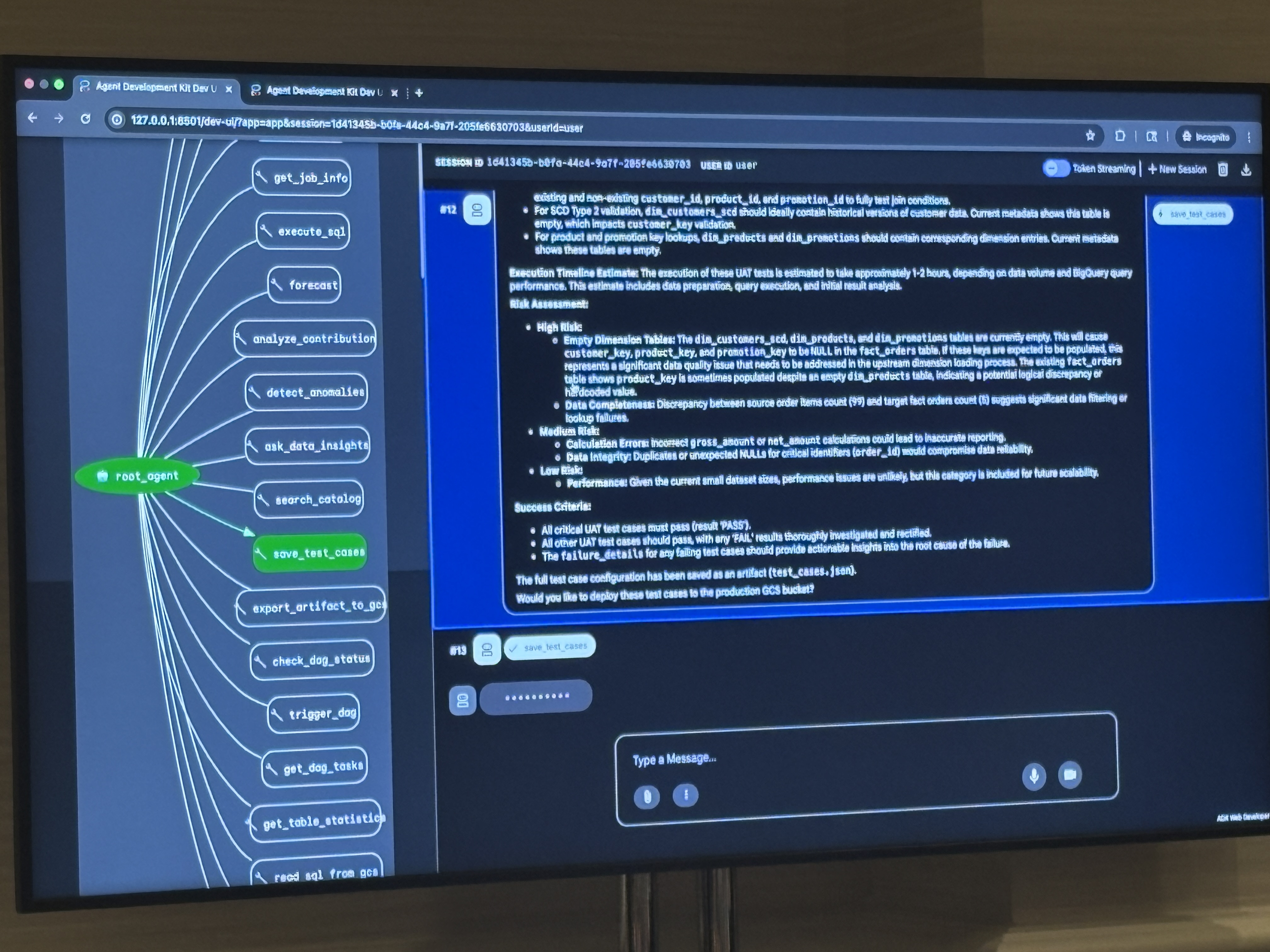
High Risk・Medium Risk・Low Riskの3段階でリスク評価が付き、各テストケースに一意のIDと成功基準が明記されます。「deploy to GCS?」という確認に「yes」と答えると、config.jsonをComposerバケットに書き込みます。「trigger DAG?」に「yes trigger dag」と返すとComposerが起動しました。
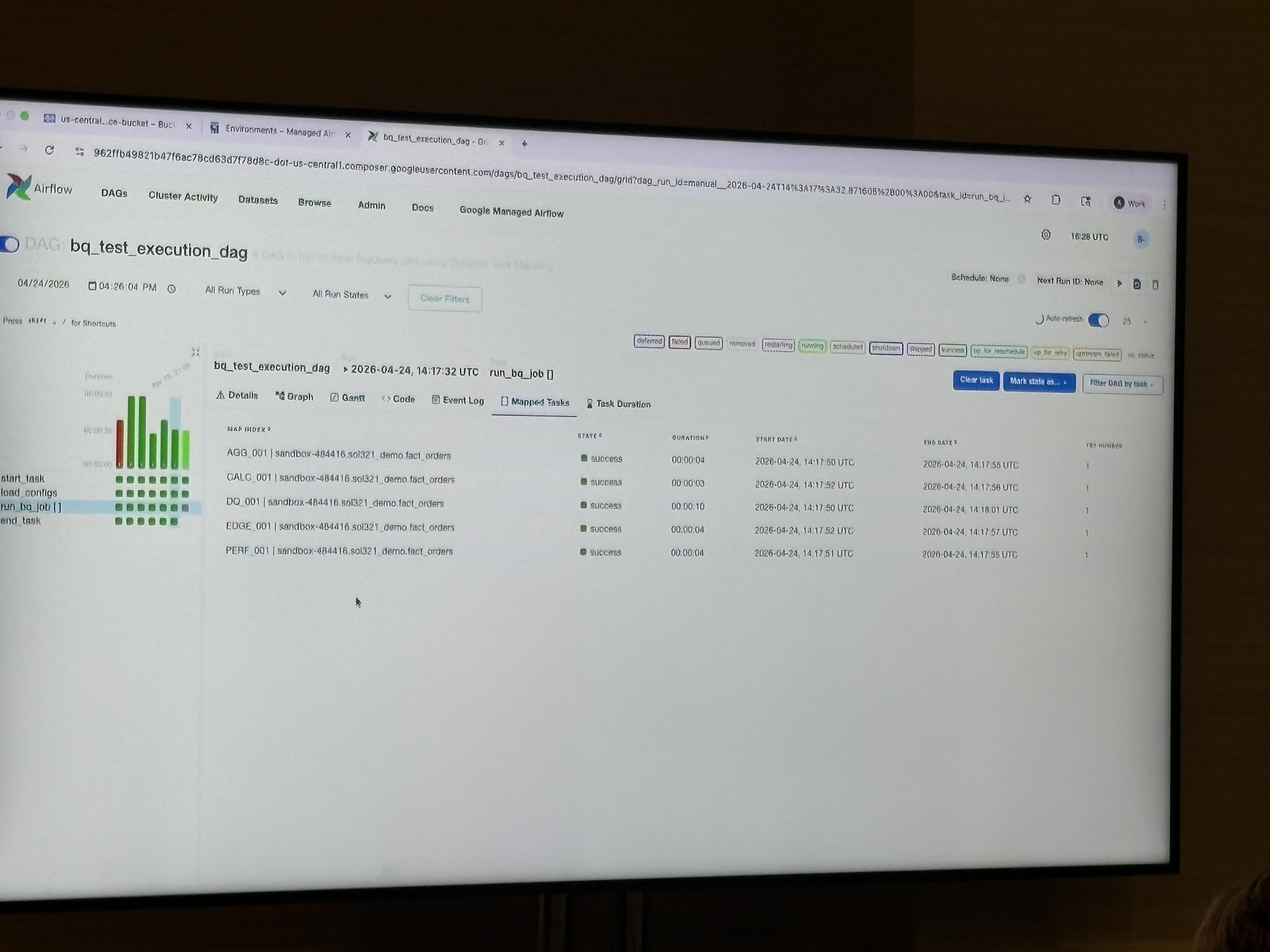
Managed Service for Apache AirflowのDAGが実行され、AGG_001・CALC_001・DQ_001・EDGE_001・PERF_001の5カテゴリすべてが数秒〜10秒以内にsuccessになっていました。
自然言語でSQLを渡してエンターを押して進めるだけで、あとはAIエージェントとApache Airflowが全て自動化されるので、従来の検証フローにかかっていた工数がかなり削減できていますね。
セッションを振り返って
「バリデーションクエリを手書きするのに何日もかかっていて、このワークフローを取り入れたことで検証のことを考えなくて良くなった」というコメントが一番リアルに感じました。
技術的に参考になったのが「データ型でグルーピングしてチャンクする」という発想です。
スキーマが大きいときに単純に列数で割るのではなく、タイムスタンプ系をまとめてプロンプトを統一するというアプローチはもし今後のプロジェクトでデータ整理を行なっていく際に参考になりました。
また「10xのスケールを想定して設計せよ」という言葉も印象に残りました。
今必要十分なサイズではなく、10倍になったとしても壊れないような設計意識を持っておくことの大切さを改めて感じました。




