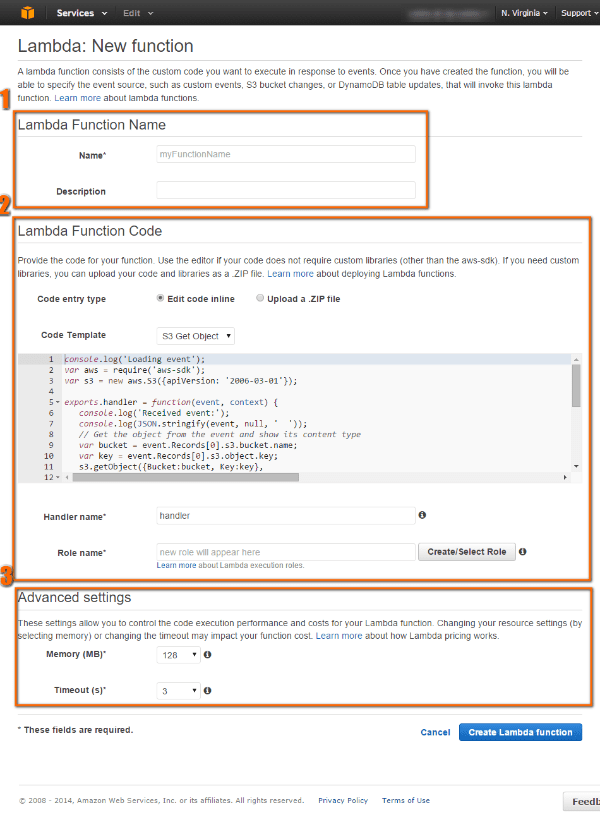
こんにちは、cloudpack の @dz_ こと大平かづみです。
Prologue – はじめに
cloudpackに在籍しておりますが、前職まではプログラマの私。
そんなインフラに憧れる一介のプログラマが、運用ツールに初挑戦のシリーズ第一弾!
(続くのでしょうか…!)
出会い
先日、「Code the Clouds Mix-up Vol.2」に参加してきました!
と言っても、駆け付けた時間は、LTの時間でした(汗)
そのLTは、「Serf / Consul 入門 ~仕事を楽しくしよう~」 by @zembutsu さん
これが運用ツールとの華麗なる出会いでありました☆
Serf と Consul
このcloudpack技術ブログでも、Serf や Consul の話題をよく見かけます。
どう便利なの?
Serf や Consul などの運用ツールは、なにを便利にしてくれるのでしょうか?
答え: 既存の業務フローを変更せずに省力化
確かに、携わる環境がすべて新規で構築できるとは限りません。既存のフローは変えずに手間を減らしていく、それを助けてくれるツールなら、ぜひ試してみたい!
でも…
「インフラ初心者の私でも、扱えるものなんだろうか?」
さっそく、LT発表された@zenbutsuさんに聞いてみました!
Serf を試すべき理由
今回LTのテーマに挙がった 2つの運用ツール Serf と Consul のうち、小規模で手軽に使い出すには、 Serf をお勧めしてもらいました。
- 機能が必要最小限で、シンプルに扱える
- 管理サーバが不要で、クラスタ構成が用意
その理由も含め、SerfとConsulの特徴や違いについて、スライド資料に書かれていました。
考えてるだけではわかりません、さっそく Serf を触ってみましょう!!
まずはドキュメントからわかること
Serfの特徴
- 主要なプラットフォームで利用可能(Linux, Mac OS X, Windows)
- 常駐メモリが小さく、軽量
- UDPの通信
Serfの主な機能は3つ
- メンバーシップの管理(ノード管理)
- 障害検知とリカバリ
- イベントのカスタマイズ
gossipプロトコルを用いて、素早く効率的なノード管理ができます。サーバーが不要で、Serfをインストールしてエージェントを起動するだけで、クラスタの生成や参加ができます。
また、各ノードが定期的に通信して生存確認を行い続けるので、障害検知がすばやく、リカバリも早いとのこと。
ノードの参加や離脱、デプロイやプロセスのリスタートなどの任意のトリガでイベントやクエリを発行することもできます。
Serf トップページとイントロダクションについて訳したものを、こちらにまとめました。ご参考になれば幸いです。
「Getting Started: Serf ~ ドキュメントを読んでみます – Qiita」
Serf をはじめよう
インストールは簡単
インストールは簡単、解凍して置くだけです!
こちらの「Downloads – Serf by HashiCorp」からパッケージを入手してください。
2014.12.16 現在、Serf のバージョンは 0.6.3 です。FreeBSD, Linux, Max OS X, OpenBSD, Windows 向けにビルドされたパッケージが用意されています。これ以外のディストリビューションの場合は「コンパイルについて(Developing Serf)」を参考に環境に合わせて準備してください。
以下は、Amazon Linux でインストールした際の手順メモです。
# - パッケージを取得する
[user@ip-xx-xx-xx-xx ~]$ wget https://dl.bintray.com/mitchellh/serf/0.6.3_linux_amd64.zip
--2014-12-15 22:28:06-- https://dl.bintray.com/mitchellh/serf/0.6.3_linux_amd64.zip
Resolving dl.bintray.com (dl.bintray.com)... 108.168.194.92, 108.168.194.91
... # 略
Saving to: ‘0.6.3_linux_amd64.zip’
0.6.3_linux_amd64.zip 100%[=================================================>] 2.86M 702KB/s in 4.6s
2014-12-15 22:28:12 (638 KB/s) - ‘0.6.3_linux_amd64.zip’ saved [3002701/3002701]
[user@ip-xx-xx-xx-xx ~]$ ls
0.6.3_linux_amd64.zip
# - 解凍
[user@ip-xx-xx-xx-xx ~]$ unzip 0.6.3_linux_amd64.zip
Archive: 0.6.3_linux_amd64.zip
inflating: serf
[user@ip-xx-xx-xx-xx ~]$ ls
0.6.3_linux_amd64.zip serf
# - PATHが通っているディレクトリへコピー
[user@ip-xx-xx-xx-xx ~]$ sudo cp serf /usr/local/bin
# - 動作確認
[user@ip-xx-xx-xx-xx ~]$ serf
usage: serf [--version] [--help] []
Available commands are:
agent Runs a Serf agent
event Send a custom event through the Serf cluster
force-leave Forces a member of the cluster to enter the "left" state
info Provides debugging information for operators
join Tell Serf agent to join cluster
keygen Generates a new encryption key
keys Manipulate the internal encryption keyring used by Serf
leave Gracefully leaves the Serf cluster and shuts down
members Lists the members of a Serf cluster
monitor Stream logs from a Serf agent
query Send a query to the Serf cluster
reachability Test network reachability
tags Modify tags of a running Serf agent
version Prints the Serf version
ちなみに、Mac OS では、homebrew を利用できるそうです。(cask プラグインが必要)
(執筆時では試してません。)
brew cask install serf
その他インストールについては、原文「Installing Serf – Serf by HashiCorp」をご参照下さい。
クラスタ最初の一歩、エージェントを起動してみる
ドキュメントに従って、エージェントを起動してみます。
以下のように、起動したまま待機状態になります。
# - エージェント起動
[user@ip-xx-xx-xx-xx ~]$ serf agent
==> Starting Serf agent...
==> Starting Serf agent RPC...
==> Serf agent running!
Node name: 'ip-xx-xx-xx-xx'
Bind addr: '0.0.0.0:7946'
RPC addr: '127.0.0.1:7373'
Encrypted: false
Snapshot: false
Profile: lan
==> Log data will now stream in as it occurs:
2014/12/15 23:12:11 [INFO] agent: Serf agent starting
2014/12/15 23:12:11 [INFO] serf: EventMemberJoin: ip-xx-xx-xx-xx xx.xx.xx.xx
2014/12/15 23:12:12 [INFO] agent: Received event: member-join
この状態で、なにかイベントがあると、ログが追記されていきます。
起動した直後では、既に、以下のようなログが表示されています。
agent: Serf agent starting- このエージェントが起動
serf: EventMemberJoin: ip-xx-xx-xx-xx xx.xx.xx.xx- Serf側でメンバーの参加イベント
agent: Received event: member-join- エージェント側でメンバー参加イベントを受信
エージェントを終了するには、Ctrl + c を押下 (割り込みシグナルを発行) してください。
すると、エージェントへ割り込みが行われ、正常に終了処理を行い終了する様子が出力されます。
# - Ctrl + C 押下でエージェント終了
==> Caught signal: interrupt
==> Gracefully shutting down agent...
2014/12/15 23:13:23 [INFO] agent: requesting graceful leave from Serf
2014/12/15 23:13:23 [INFO] serf: EventMemberLeave: ip-xx-xx-xx-xx xx.xx.xx.xx
2014/12/15 23:13:23 [INFO] agent: requesting serf shutdown
2014/12/15 23:13:23 [INFO] agent: shutdown complete
正常に終了できました!
エージェント終了の2つのケース「離脱」と「障害」
さて、この終了処理でエージェントが何をしているかというと、クラスタのほかのメンバーに自身が離脱することを通知しているのです。
仮にエージェントプロセスを強制的に終了した場合は、この通知が行われないので、クラスタのメンバーたちは、そのノードは障害が起きたのだと検知するのだそうです。
実は、この2つの動作の違いがSerfでは重要な要素なんです。
なぜかというと、Serfは、障害が起きたノードに対しては自動的に再接続を試み、復帰してくることを許します。
一方で、意図的に離脱したノードに対してはもう通信はしないので、無駄な通信が抑えられます。
このことについては、次回に実際に確認してみたいです。
メンバーシップを実感してみる
さて、もっとエージェントの動きを見てみますしょう!
serf agent で再びエージェントを起動します。
[user@ip-xx-xx-xx-xx ~]$ serf agent
==> Starting Serf agent...
==> Starting Serf agent RPC...
==> Serf agent running!
Node name: 'ip-172-31-1-18'
Bind addr: '0.0.0.0:7946'
RPC addr: '127.0.0.1:7373'
Encrypted: false
Snapshot: false
Profile: lan
==> Log data will now stream in as it occurs:
2014/12/18 13:15:05 [INFO] agent: Serf agent starting
2014/12/18 13:15:05 [INFO] serf: EventMemberJoin: ip-xx-xx-xx-xx xx.xx.xx.xx
2014/12/18 13:15:06 [INFO] agent: Received event: member-join
ここで、別のセッションで接続して、serf membersコマンドを実行してみます。
別セッションで接続するには、私は Windows で iceiv+putty を使ってアクセスしているので、もう一つウィンドウを立ち上げてアクセスしました。
[user@ip-xx-xx-xx-xx ~]$ serf members
ip-xx-xx-xx-xx xx.xx.xx.xx:7946 alive
なんということでしょう!♪
[user@ip-xx-xx-xx-xx ~]$ serf agent
==> Starting Serf agent...
==> Starting Serf agent RPC...
==> Serf agent running!
Node name: 'ip-xx-xx-xx-xx'
Bind addr: '0.0.0.0:7946'
RPC addr: '127.0.0.1:7373'
Encrypted: false
Snapshot: false
Profile: lan
==> Log data will now stream in as it occurs:
2014/12/18 13:15:05 [INFO] agent: Serf agent starting
2014/12/18 13:15:05 [INFO] serf: EventMemberJoin: ip-xx-xx-xx-xx xx.xx.xx.xx
2014/12/18 13:15:06 [INFO] agent: Received event: member-join
2014/12/18 13:15:25 [INFO] agent.ipc: Accepted client: 127.0.0.1:53399 # <- serf members を実行した直後に、この1行が表示されました
最後の行が追加され、クラスタへのアクセスがちゃんと検知されたことがわかります。
ぱちぱちぱち!
複数ノードでガチャガチャしたい!
先走って「Join a Cluster (クラスタへの参加)」に突入したのですが、Vagrantを使って、複数ノードのクラスタをシミュレートしていくようです。これを進めるとまた1週間くらいを要してしまいそうなので、本記事ではいったん一区切りとします。
すぐに試していきますけど!♪
Epilogue – おわりに
さて、初めて運用ツールに触れてみた感想です。
インフラは本業でないので、かなり手探り状態ですが、Serf について読んで触ってみて、運用のことが少しわかってきたような気がして楽しいです。
まだ準備ができただけで何も運用してません。複数ノードの動作を早く動かしたくてうずうずしています。
まだまだこれからです!
よろしくお願いします!